Checkpoints
Add Cloud Data Fusion API Service Agent role to service account
/ 25
Setup Cloud Storage bucket
/ 25
Deploy and execute the pipeline
/ 50
Creating Reusable Pipelines in Cloud Data Fusion
- GSP810
- Overview
- Setup and requirements
- Task 1. Add necessary permissions for your Cloud Data Fusion instance
- Task 2. Set up the Cloud Storage bucket
- Task 3. Navigate to the Cloud Data Fusion UI
- Task 4. Deploy the Argument Setter plugin
- Task 5. Read from Cloud Storage
- Task 6. Transform your data
- Task 7. Write to Cloud Storage
- Task 8. Set the macro arguments
- Task 9. Deploy and run your pipeline
- Congratulations!
GSP810

Overview
In this lab you will learn how to build a reusable pipeline that reads data from Cloud Storage, performs data quality checks, and writes to Cloud Storage.
Objectives
What you'll learn
- How to use the Argument Setter plugin to allow the pipeline to read different input in every run.
- How to use the Argument Setter plugin to allow the pipeline to perform different quality checks in every run.
- How to write the output data of each run to Cloud Storage.
Setup and requirements
For each lab, you get a new Google Cloud project and set of resources for a fixed time at no cost.
-
Sign in to Google Cloud Skills Boost using an incognito window.
-
Note the lab's access time (for example, 02:00:00), and make sure you can finish within that time.
There is no pause feature. You can restart if needed, but you have to start at the beginning. -
When ready, click Start lab.
Note: Once you click Start lab, it will take about 15 - 20 minutes for the lab to provision necessary resources and create a Data Fusion instance. During that time, you can read through the steps below to get familiar with the goals of the lab. When you see lab credentials (Username and Password) in the left panel, the instance is created and you can continue logging into the console. -
Note your lab credentials (Username and Password). You will use them to sign in to the Google Cloud console.
-
Click Open Google console.
-
Click Use another account and copy/paste credentials for this lab into the prompts.
If you use other credentials, you'll receive errors or incur charges. -
Accept the terms and skip the recovery resource page.
Log in to Google Cloud Console
- Using the browser tab or window you are using for this lab session, copy the Username from the Connection Details panel and click the Open Google Console button.
- Paste in the Username, and then the Password as prompted.
- Click Next.
- Accept the terms and conditions.
Since this is a temporary account, which will last only as long as this lab:
- Do not add recovery options
- Do not sign up for free trials
- Once the console opens, view the list of services by clicking the Navigation menu (
) at the top-left.

Activate Cloud Shell
Cloud Shell is a virtual machine that contains development tools. It offers a persistent 5-GB home directory and runs on Google Cloud. Cloud Shell provides command-line access to your Google Cloud resources. gcloud is the command-line tool for Google Cloud. It comes pre-installed on Cloud Shell and supports tab completion.
-
Click the Activate Cloud Shell button (
) at the top right of the console.
-
Click Continue.
It takes a few moments to provision and connect to the environment. When you are connected, you are also authenticated, and the project is set to your PROJECT_ID.
Sample commands
- List the active account name:
(Output)
(Example output)
- List the project ID:
(Output)
(Example output)
Check project permissions
Before you begin working on Google Cloud, you must ensure that your project has the correct permissions within Identity and Access Management (IAM).
-
In the Google Cloud console, on the Navigation menu (
-
Confirm that the default compute Service Account
{project-number}-compute@developer.gserviceaccount.comis present and has theeditorrole assigned. The account prefix is the project number, which you can find on Navigation menu > Cloud overview.

If the account is not present in IAM or does not have the editor role, follow the steps below to assign the required role.
-
In the Google Cloud console, on the Navigation menu, click Cloud overview.
-
From the Project info card, copy the Project number.
-
On the Navigation menu, click IAM & Admin > IAM.
-
At the top of the IAM page, click Add.
-
For New principals, type:
Replace {project-number} with your project number.
-
For Select a role, select Basic (or Project) > Editor.
-
Click Save.
Task 1. Add necessary permissions for your Cloud Data Fusion instance
- In the Google Cloud console, from the Navigation menu select Data Fusion > Instances.
Next, you will grant permissions to the service account associated with the instance, using the following steps.
-
From the Google Cloud console, navigate to the IAM & Admin > IAM.
-
Confirm that the Compute Engine Default Service Account
{project-number}-compute@developer.gserviceaccount.comis present, copy the Service Account to your clipboard. -
On the IAM Permissions page, click +Grant Access.
-
In the New principals field paste the service account.
-
Click into the Select a role field and start typing "Cloud Data Fusion API Service Agent", then select it.
-
Click Save.
Click Check my progress to verify the objective.
Grant service account user permission
-
In the console, on the Navigation menu, click IAM & admin > IAM.
-
Select the Include Google-provided role grants checkbox.
-
Scroll down the list to find the Google-managed Cloud Data Fusion service account that looks like
service-{project-number}@gcp-sa-datafusion.iam.gserviceaccount.comand then copy the service account name to your clipboard.

-
Next, navigate to the IAM & admin > Service Accounts.
-
Click on the default compute engine account that looks like
{project-number}-compute@developer.gserviceaccount.com, and select the Permissions tab on the top navigation. -
Click on the Grant Access button.
-
In the New Principals field, paste the service account you copied earlier.
-
In the Role dropdown menu, select Service Account User.
-
Click Save.
Task 2. Set up the Cloud Storage bucket
Next, you will create a Cloud Storage bucket in your project to be used later to store results when your pipeline runs.
-
In Cloud Shell, execute the following commands to create a new bucket:
export BUCKET=$GOOGLE_CLOUD_PROJECT gcloud storage buckets create gs://$BUCKET
The created bucket has the same name as your Project ID.
Click Check my progress to verify the objective.
Task 3. Navigate to the Cloud Data Fusion UI
-
In the Cloud Console, from the Navigation Menu, click on Data Fusion, then click the View Instance link next to your Data Fusion instance. Select your lab credentials to sign in, if required.
-
If prompted to take a tour of the service click on No, Thanks. You should now be in the Cloud Data Fusion UI.
Task 4. Deploy the Argument Setter plugin
- In the Cloud Data Fusion web UI, click Hub on the upper right.
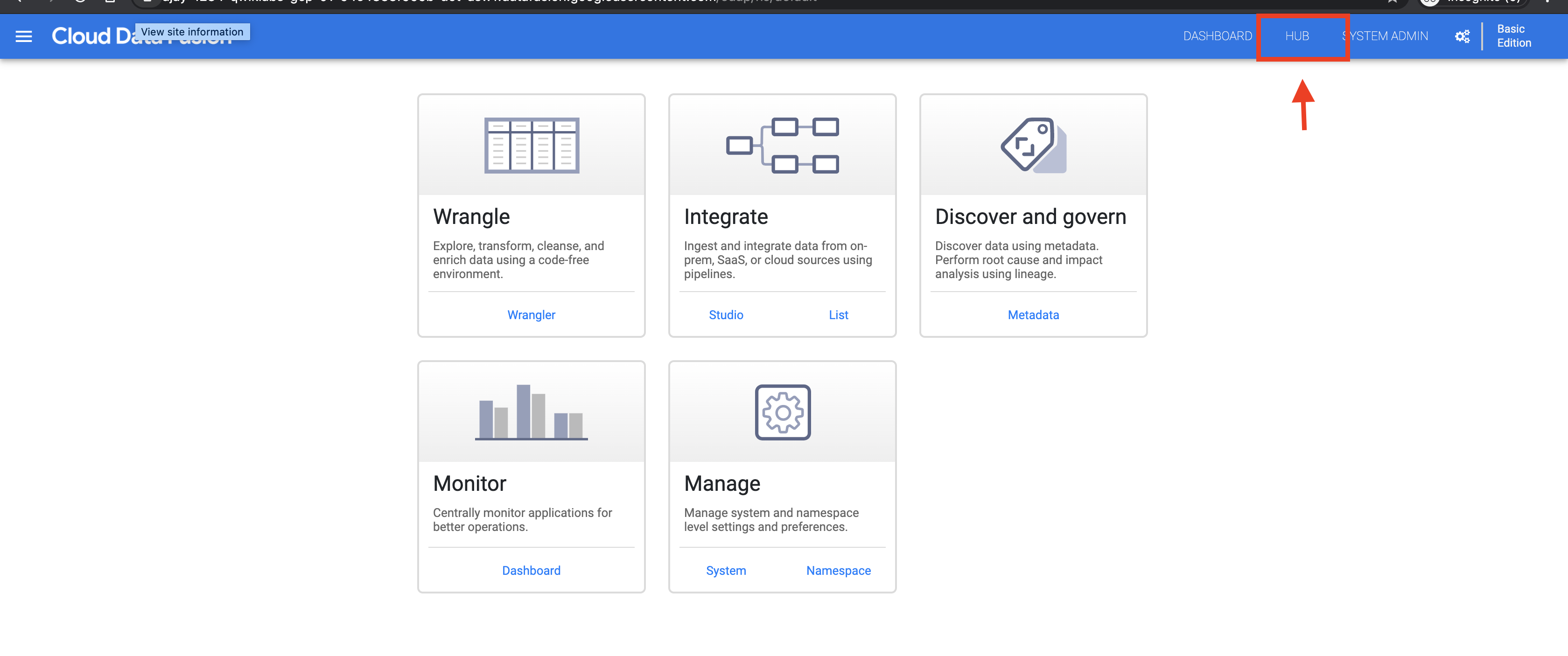
-
Click the Argument setter action plugin and click Deploy.
-
In the Deploy window that opens, click Finish.
-
Click Create a pipeline. The Pipeline Studio page opens.
Task 5. Read from Cloud Storage
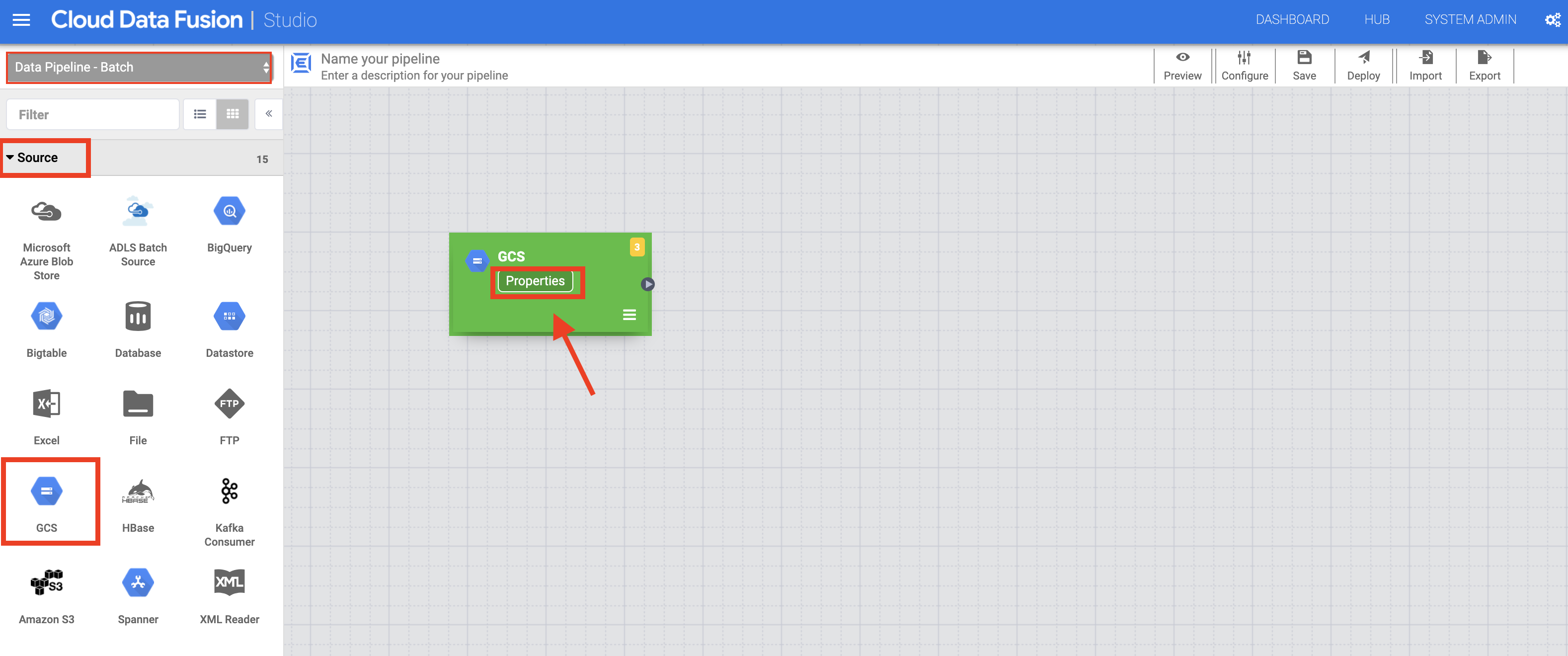
-
In the left panel of the Pipeline Studio page, using the Source drop-down menu, select Google Cloud Storage.
-
Hover over the Cloud Storage node and click the Properties button that appears.
-
In the Reference name field, enter a name.
-
In the Path field, enter
${input.path}. This macro controls what the Cloud Storage input path will be in the different pipeline runs. -
In the Format field, select text.
-
In the right Output Schema panel, remove the offset field from the output schema by clicking the trash icon in the offset field row.
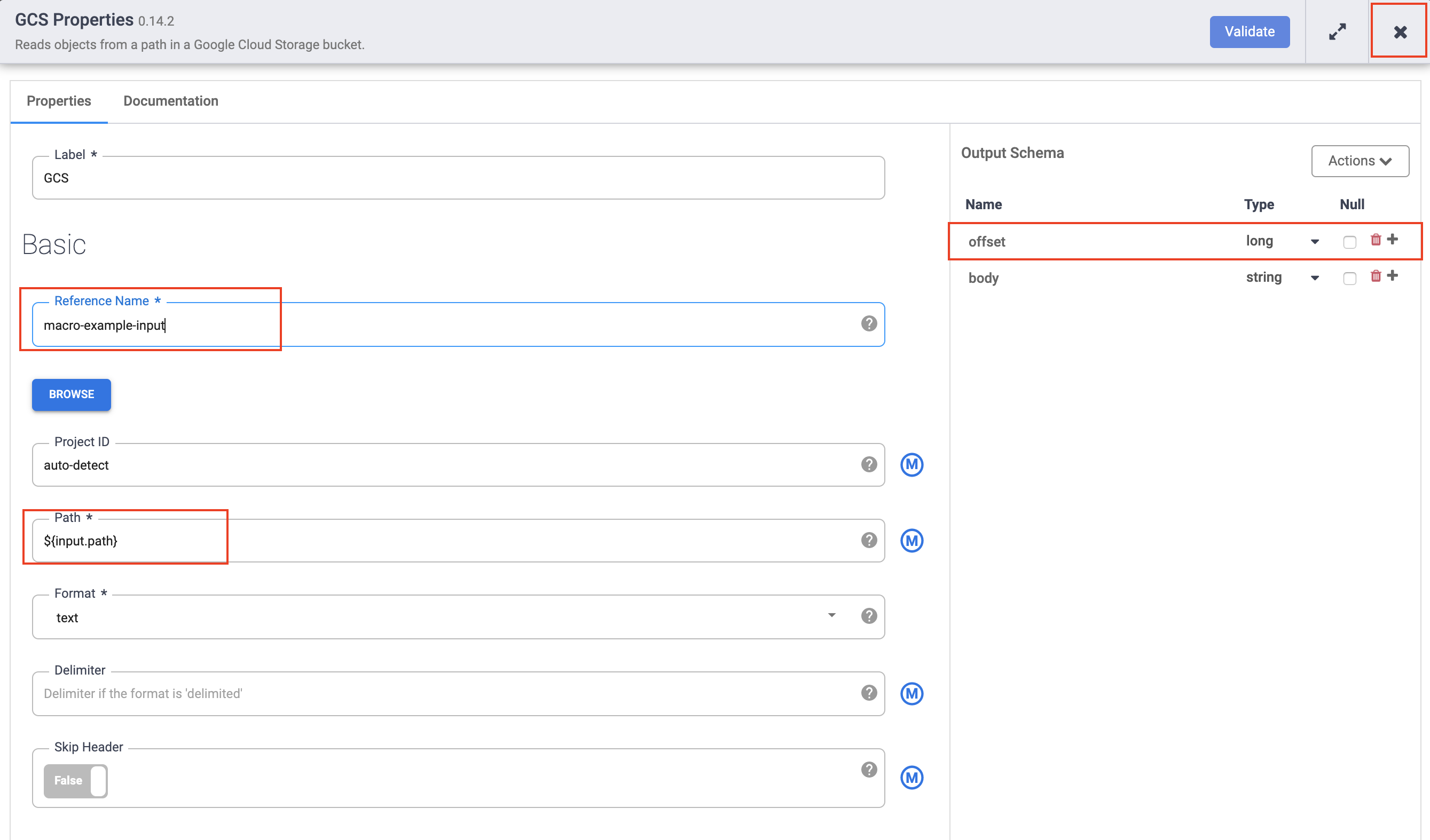
- Click the X button to exit the Properties dialog box.
Task 6. Transform your data
-
In the left panel of the Pipeline Studio page, using the Transform drop-down menu, select Wrangler.
-
In the Pipeline Studio canvas, drag an arrow from the Cloud Storage node to the Wrangler node.
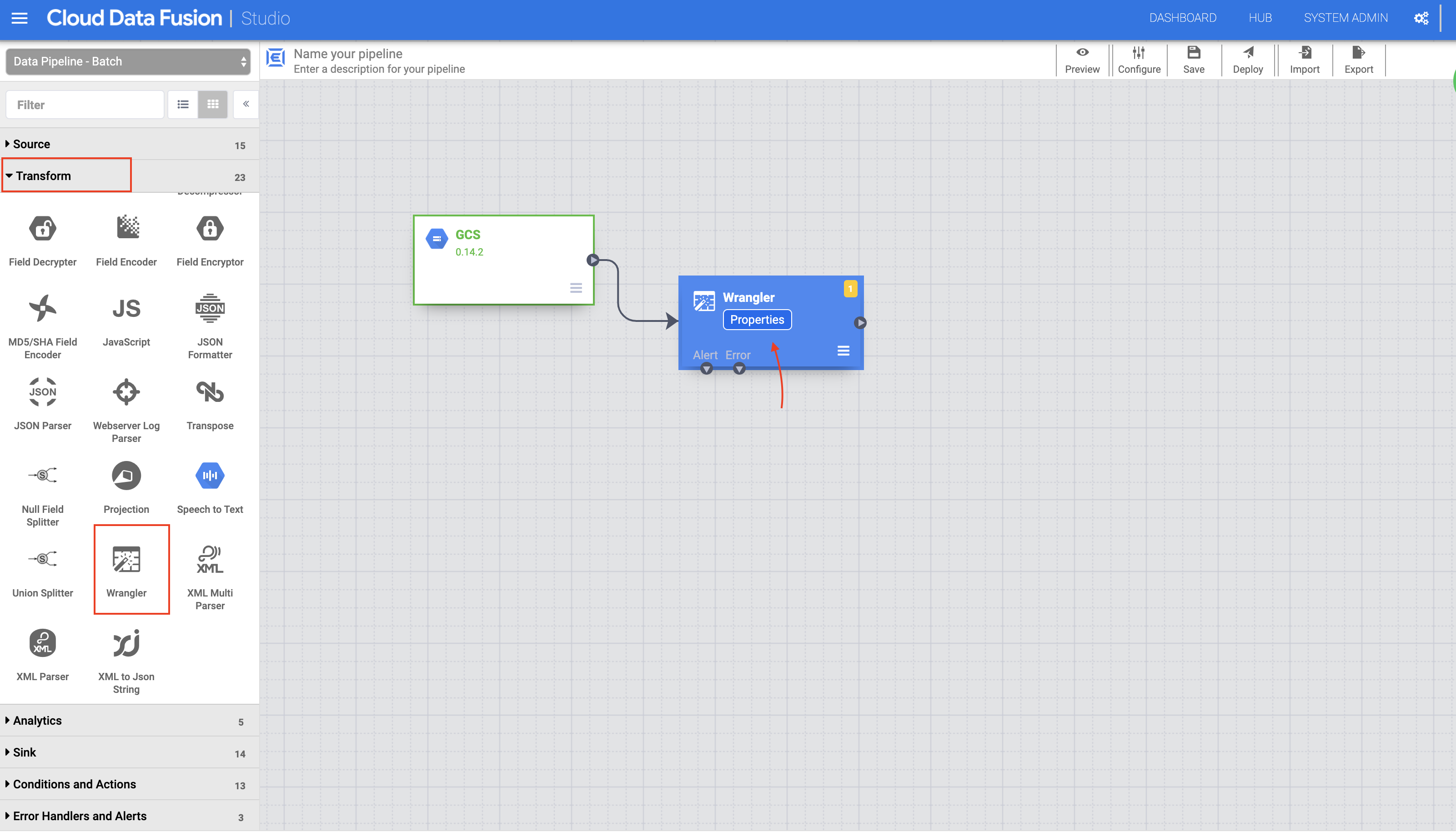
-
Hover over the Wrangler node and click the Properties button that appears.
-
In the Input field name, type
body. -
In the Recipe field, enter
${directives}. This macro controls what the transform logic will be in the different pipeline runs.
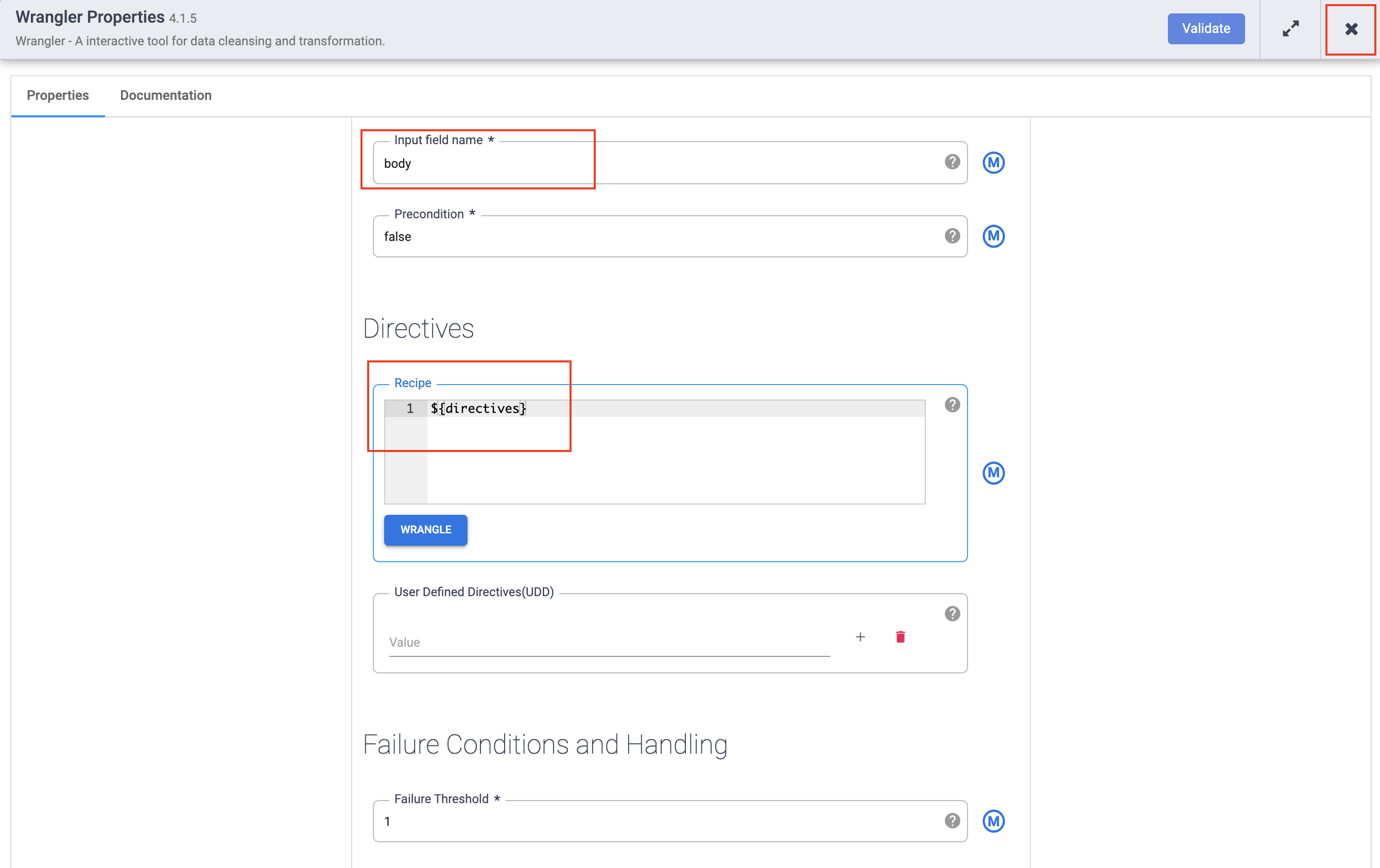
- Click the X button to exit the Properties dialog box.
Task 7. Write to Cloud Storage
-
In the left panel of the Pipeline Studio page, using the Sink drop-down menu, select Cloud Storage.
-
On the Pipeline Studio canvas, drag an arrow from the Wrangler node to the Cloud Storage node you just added.
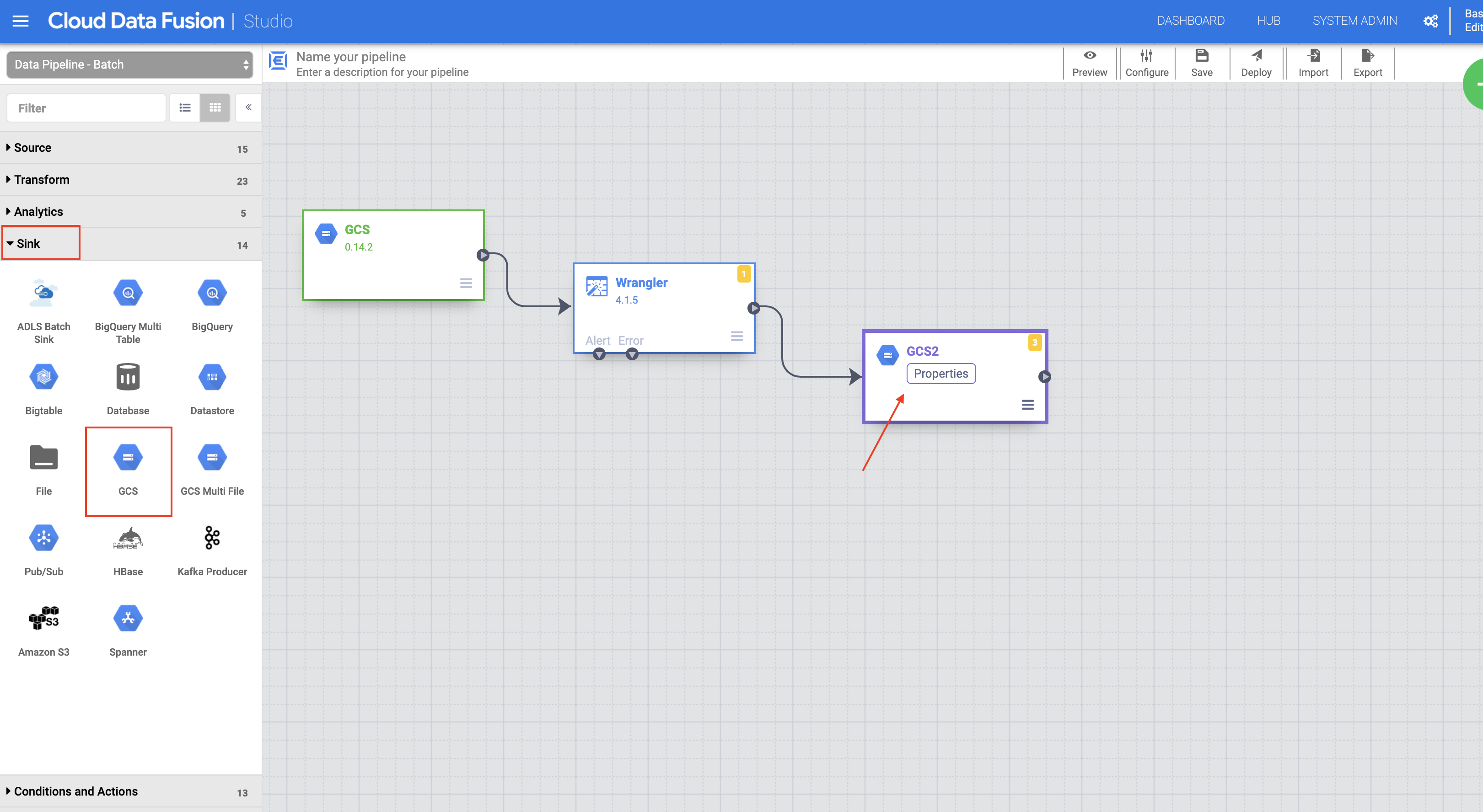
-
Hover over the Cloud Storage sink node and click the Properties button that appears.
-
In the Reference name field, enter a name.
-
In the Path field, enter the path of your Cloud Storage bucket you created earlier.
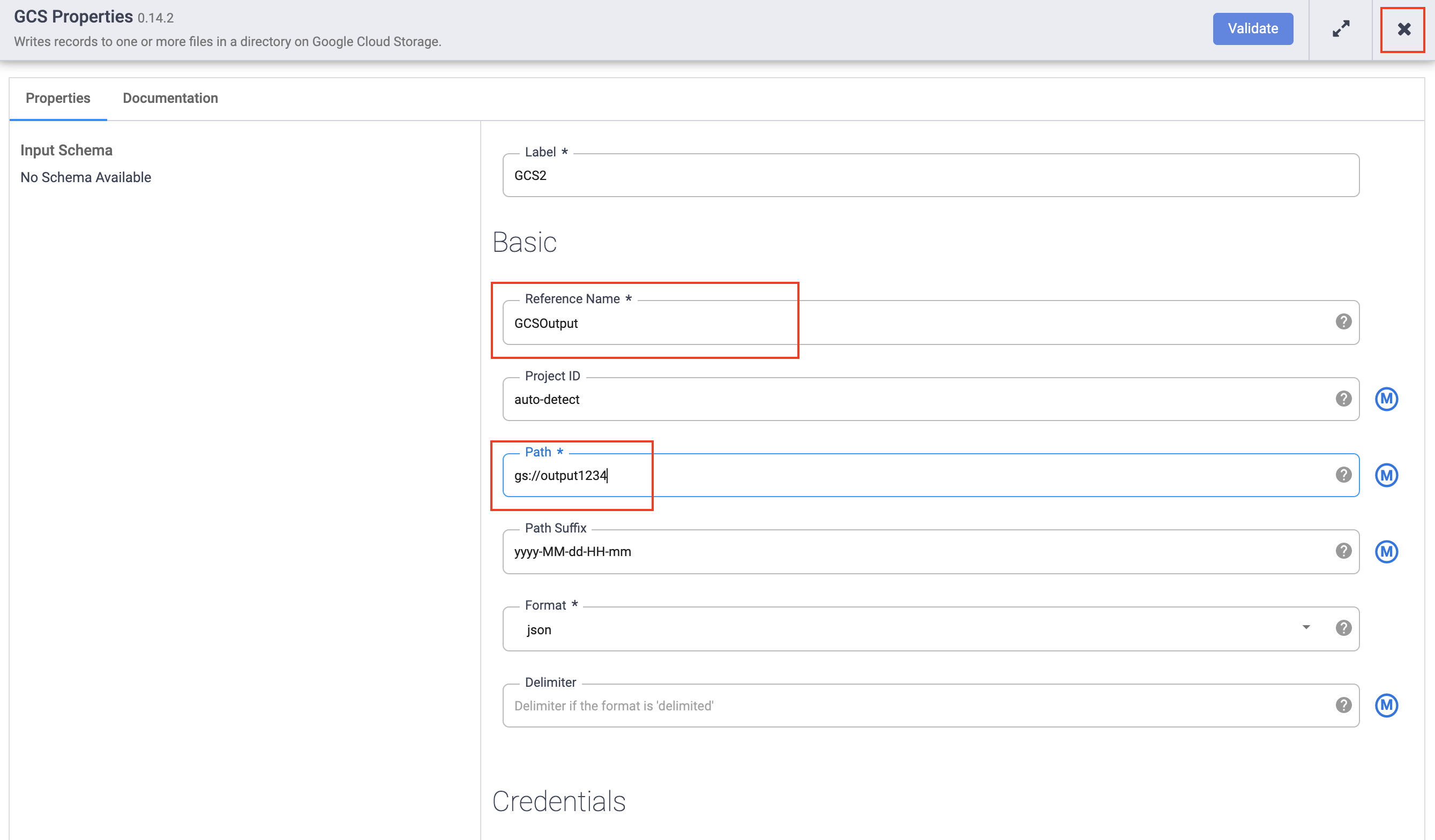
-
In the Format field, select json.
-
Click the X button to exit the Properties menu.
Task 8. Set the macro arguments
-
In the left panel of the Pipeline Studio page, using the Conditions and Actions drop-down menu, select the Argument Setter plugin.
-
In the Pipeline Studio canvas, drag an arrow from the Argument Setter node to the Cloud Storage source node.
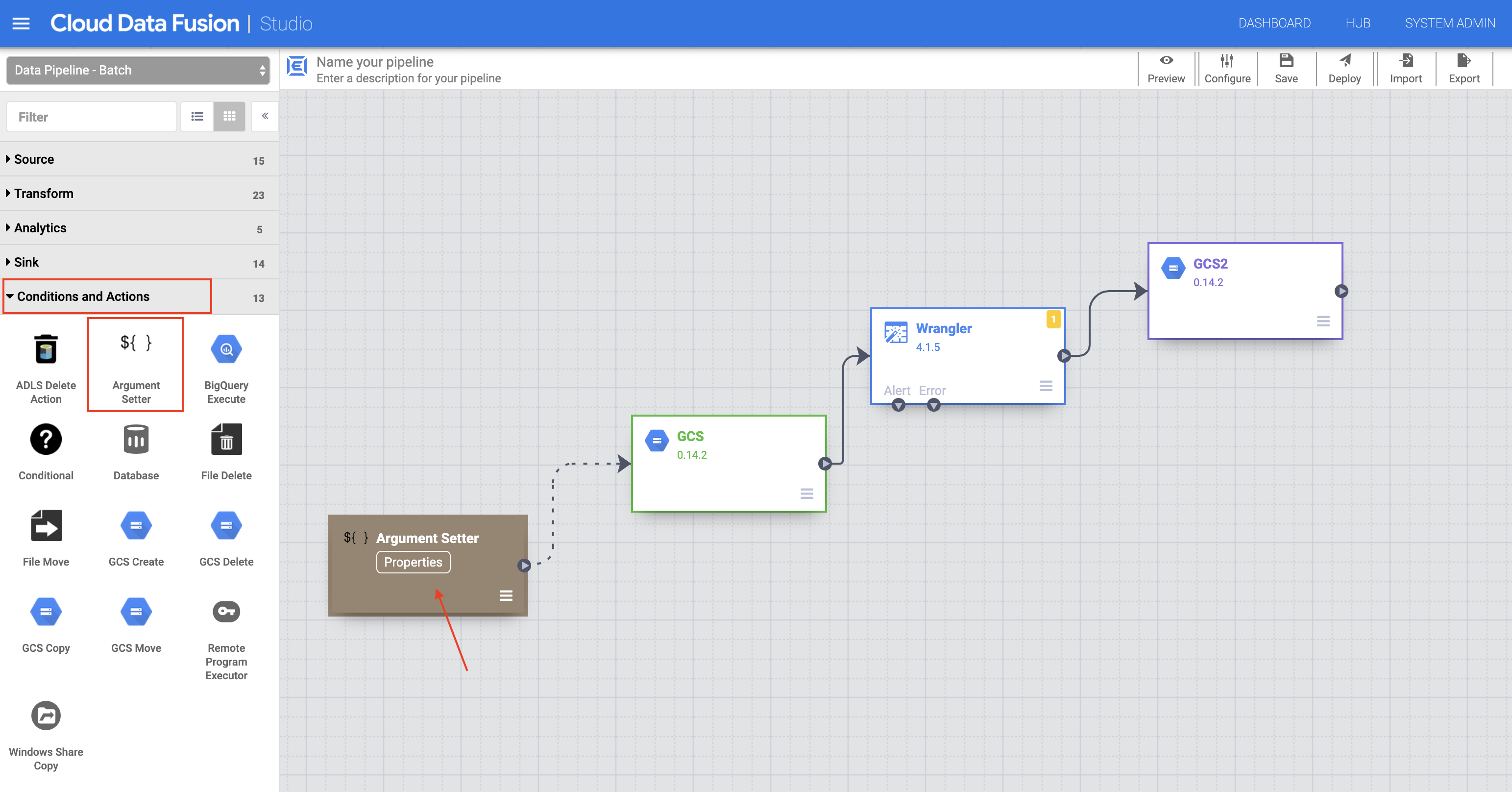
-
Hover over the Argument Setter node and click the Properties button that appears.
-
In the URL field, add the following:
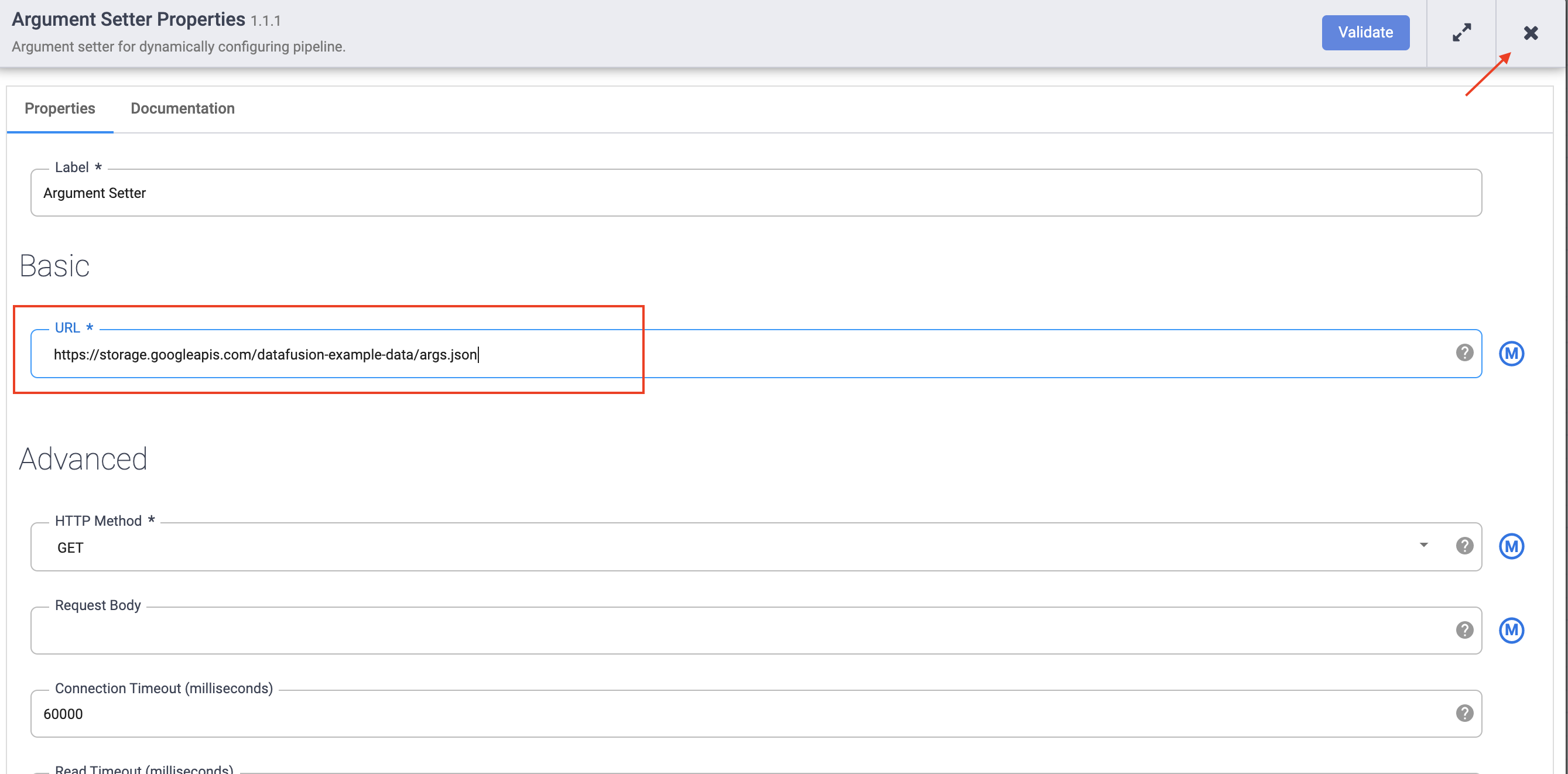
The URL corresponds to a publicly accessible object in Cloud Storage that contains the following content:
The first of the two arguments is the value for input.path. The path gs://reusable-pipeline-tutorial/user-emails.txt is a publicly accessible object in Cloud Storage that contains the following test data:
The second argument is the value for directives. The value send-to-error !dq:isEmail(body) configures Wrangler to filter out any lines that are not a valid email address. For example, craig@invalid@example.com is filtered out.
- Click the X button to exit the Properties menu.
Task 9. Deploy and run your pipeline
- In the top bar of the Pipeline Studio page, click Name your pipeline. Give your pipeline a name (like
Reusable-Pipeline), and then click Save.
-
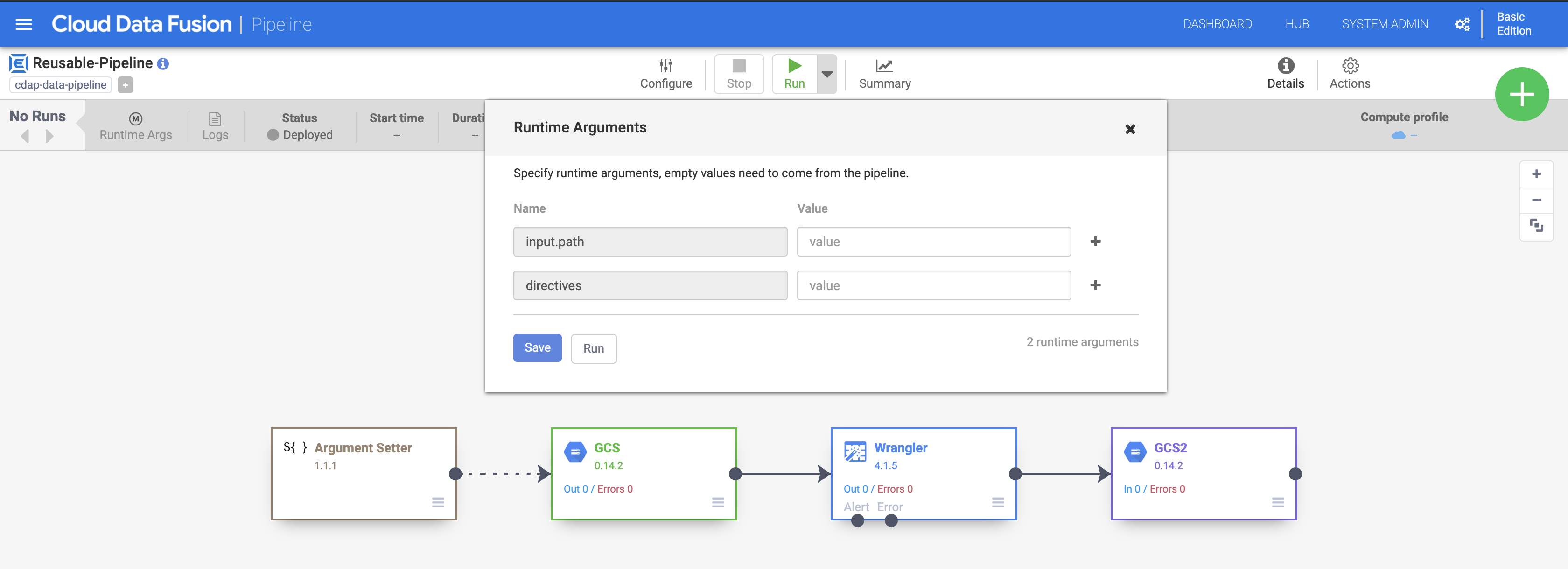
Click Deploy on the top right of the Pipeline Studio page. This will deploy your pipeline.
-
Once deployed, click the drop-down menu on the Run button. Notice the boxes for the
input.pathanddirectivesarguments. This notifies Cloud Data Fusion that the pipeline will set values for these required arguments during runtime provided through the Argument Setter plugin. Click Run. -
Wait for the pipeline run to complete and the status to change to Succeeded.
Click Check my progress to verify the objective.
Congratulations!
In this lab, you have learned how to use the Argument Setter plugin to create a reusable pipeline, which can take in different input arguments with every run.
Continue your quest
This self-paced lab is part of the Building Advanced Codeless Pipelines on Cloud Data Fusion quest. A quest is a series of related labs that form a learning path. Completing this quest earns you a badge to recognize your achievement. You can make your badge or badges public and link to them in your online resume or social media account. Enroll in this quest and get immediate completion credit. Refer to the Google Cloud Skills Boost catalog for all available quests.
Take your next lab
Continue your quest with Redacting Confidential Data within your Pipelines in Cloud Data Fusion.
Manual Last Updated November 14, 2022
Lab Last Tested October 11, 2022
Copyright 2022 Google LLC All rights reserved. Google and the Google logo are trademarks of Google LLC. All other company and product names may be trademarks of the respective companies with which they are associated.