チェックポイント
Create the firewall rule
/ 100
ネットワーク パフォーマンスの改善 l
GSP045

概要
このハンズオンラボでは、現実のシナリオをいくつか読んでその環境を再現し、問題のあるネットワークのパフォーマンスを改善します。
トラブル シューティングのユースケースと同じように、さまざまなインスタンスを比較してみてください。そうすることで、結果を実証してシステムのパフォーマンスを改善するための手順を理解できます。
このラボは、Colt McAnlis によるブログ投稿「Core Count and the Egress problem」と「Internal IP vs External IP」を基に作成されています。Colt は Medium で Google Cloud ネットワーク パフォーマンスについて投稿しています。
目標
- オープンソース ツールを使用して、ネットワークの接続とパフォーマンスをテストする
- オープンソース ツールを使用して、ネットワーク トラフィックについて調べる
- マシンのサイズがネットワークのパフォーマンスに与える影響について確認する
前提条件
- Google Cloud サービスに関する基本的な知識があること(すでに「Google Cloud Essentials」のラボを受講していれば尚可)
- Google Cloud ネットワーキングと TCP/IP に関する基本的な知識があること(すでに「Networking in the Google Cloud」のラボを受講していれば尚可)
- Unix / Linux コマンドラインに関する基本的な知識があること
設定と要件
[ラボを開始] ボタンをクリックする前に
こちらの手順をお読みください。ラボの時間は記録されており、一時停止することはできません。[ラボを開始] をクリックするとスタートするタイマーは、Google Cloud のリソースを利用できる時間を示しています。
このハンズオンラボでは、シミュレーションやデモ環境ではなく、実際のクラウド環境を使ってご自身でラボのアクティビティを行うことができます。そのため、ラボの受講中に Google Cloud にログインおよびアクセスするための、新しい一時的な認証情報が提供されます。
このラボを完了するためには、下記が必要です。
- 標準的なインターネット ブラウザ(Chrome を推奨)
- ラボを完了するために十分な時間を確保してください。ラボをいったん開始すると一時停止することはできません。
ラボを開始して Google Cloud コンソールにログインする方法
-
[ラボを開始] ボタンをクリックします。ラボの料金をお支払いいただく必要がある場合は、表示されるポップアップでお支払い方法を選択してください。 左側の [ラボの詳細] パネルには、以下が表示されます。
- [Google コンソールを開く] ボタン
- 残り時間
- このラボで使用する必要がある一時的な認証情報
- このラボを行うために必要なその他の情報(ある場合)
-
[Google コンソールを開く] をクリックします。 ラボでリソースが起動し、別のタブで [ログイン] ページが表示されます。
ヒント: タブをそれぞれ別のウィンドウで開き、並べて表示しておきましょう。
注: [アカウントの選択] ダイアログが表示されたら、[別のアカウントを使用] をクリックします。 -
必要に応じて、[ラボの詳細] パネルから [ユーザー名] をコピーして [ログイン] ダイアログに貼り付けます。[次へ] をクリックします。
-
[ラボの詳細] パネルから [パスワード] をコピーして [ようこそ] ダイアログに貼り付けます。[次へ] をクリックします。
重要: 認証情報は左側のパネルに表示されたものを使用してください。Google Cloud Skills Boost の認証情報は使用しないでください。 注: このラボでご自身の Google Cloud アカウントを使用すると、追加料金が発生する場合があります。 -
その後次のように進みます。
- 利用規約に同意してください。
- 一時的なアカウントなので、復元オプションや 2 要素認証プロセスは設定しないでください。
- 無料トライアルには登録しないでください。
その後このタブで Cloud Console が開きます。

このラボの目標は、コアサイズとスループットの関係を学習することです。ラボにはすでに 6 つのインスタンスが組み込まれています。これらのインスタンスは、このラボを開始したときに作成されたものです。
- Cloud コンソールで、ナビゲーション メニュー > [Compute Engine] > [VM インスタンス] の順に移動して、インスタンスを表示します。
![6 つのインスタンスとその詳細を表形式で示す [VM インスタンス] のページ](https://cdn.qwiklabs.com/Cg9%2BzXSB14niqn3RwyXt7r%2FX0%2F73HOtUlK40HZ3cBTo%3D)
接続テスト
簡単な接続テストを行って、問題がないことを確認します。
-
コンソールで、インスタンス名の横にある [SSH] ボタンをクリックして、
instance-1に SSH 接続します。 -
新しいシェル ウィンドウで、次のコマンドを実行して別のインスタンスを ping します。
<external ip address of instance-2>はinstance-2の外部 IP アドレスに置き換えてください。
出力例:
- さらに、別のインスタンスを ping します。
<external ip address of instance-3>をinstance-3の外部 IP アドレスに置き換えて、instance-3 をpingします。
出力例:
問題なさそうなので、次に進みます。
ファイアウォール ルールを確認する
このラボ用にファイアウォール ルールも作成されています。
- ファイアウォール ルールを確認するには、ナビゲーション メニュー > [ネットワーキング] > [VPC ネットワーク] > [ファイアウォール] の順に移動し、
iperftestingファイアウォールをクリックします。
ファイアウォール ルール iperftesting は、以下のように設定されています。
| フィールド | 値 | コメント |
|---|---|---|
| 名前 | iperftesting | 新しいルールの名前 |
| ターゲット | ネットワーク上のすべてのインスタンス | |
| ソース IP の範囲 | 0.0.0.0/0 | インターネットからのすべての IP アドレスに対してファイアウォールを開きます。 |
| プロトコルとポート | tcp:5001; udp:5001 | |
| トラフィックの方向 | 内向き | |
| 一致したときのアクション | 許可 |
これでラボを開始できるようになりました。
ユースケース 1: ネットワーキングと Compute Engine のコア数
この最初のシナリオでは、使用しているマシンのサイズが測定可能なスループットにどのように影響するかを調べます。
Dobermanifesto はペット専用の動画ミニブログ ネットワークです。動物の動画を世界中からアップロードでき、どこにでも送信して視聴することができます。
Compute Engine バックエンドとのデータの転送中に測定された帯域幅は、期待を下回っています。
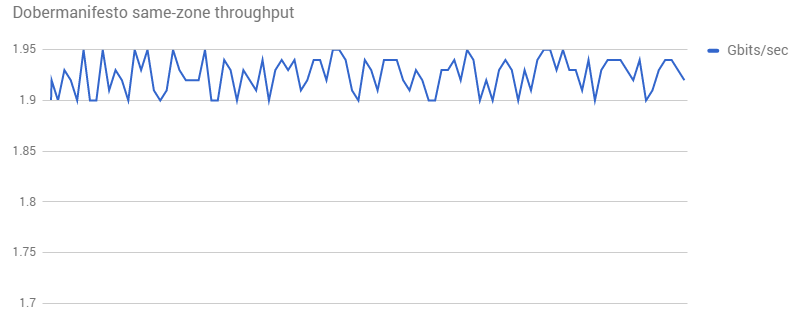
タスク 1. 動作を再現する
この動作を再現するために、同じゾーン内にインスタンスが 2 つ作成され、それらの間で iperf が 100 回実行されました。
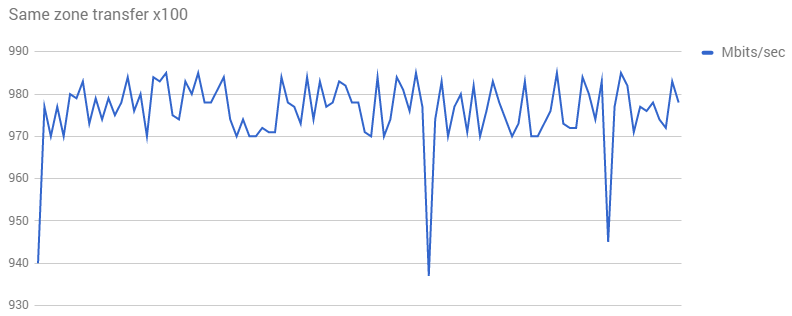
パフォーマンスはさらに悪化しました。明らかにテストに何か問題があります。Dobermanifesto から詳しい情報と詳細な再現ステップを入手する必要があります。
ここでシナリオを設定します。
Dobermanifesto の環境
-
Compute Engine コンソールの VM インスタンスのリストに戻ります。
-
instance-1(1 vCPU 3.75 GB)に SSH 接続し、次のコマンドを実行してiperfの「受信者」を設定します。
- 次に、
instance-2(1 vCPU 3.75 GB)に SSH 接続し、instance-1に対するiperfトラフィックを生成します。
出力例:
-
instance-1に戻り、CTRL + C を押して受信を終了します。
テスト環境
-
Compute Engine コンソールに戻り、
instance-6(1 vCPU e2-micro 0.6 GB)に対する別の SSH ウィンドウを開きます。 -
次のコマンドを実行し、このインスタンスを「受信者」として設定します。
出力例:
-
instance-2の SSH ウィンドウで、instance-6への接続をテストします。
出力例:
-
instance-6に戻り、CTRL + C を押して受信を終了します。
どうでしたか?上記の出力例では、帯域幅が広くなったように見えます。実際の環境でもそうなるかもしれませんし、逆に狭くなるかもしれません。
次のセクションでは、帯域幅が総コア数によってどのように制限されるかを見ていきます。この狭い範囲のコア数(コア数 1)では、帯域幅が 2 Gbit/秒を超えることはありません。そのため、ネットワーク速度は遅くなり、帯域幅は制限され、Dobermanifesto の場合と同じ結果になります。4 CPU のマシンを使用して 1 分間テストしてみると、結果はもっと良くなります。
Gb/秒と相関するコア数
結果がそれほど変わらなかったのはなぜでしょうか。Compute Engine のドキュメントには、次のように記載されています。
仮想マシンからの送信トラフィック、つまり外向きトラフィックは、最大のネットワーク外向きスループットの影響を受けます。これらの最大容量は、仮想マシン インスタンスにある vCPU の数に依存します。各コアの容量は、ピーク パフォーマンス時で 2 Gbit/秒(Gbps)です。コア数を追加することでネットワークの容量が増加し、理論的には仮想マシンごとに最大で 16 Gbps となります。
つまり、ネットワーク内の仮想 CPU の数が多いほど、ネットワーキング スループットは向上します。
これが実際にどのように見えるかを理解するために、さまざまなコアサイズ グループを同じゾーンに設定し、そこで iperf を 1,000 回実行しました。
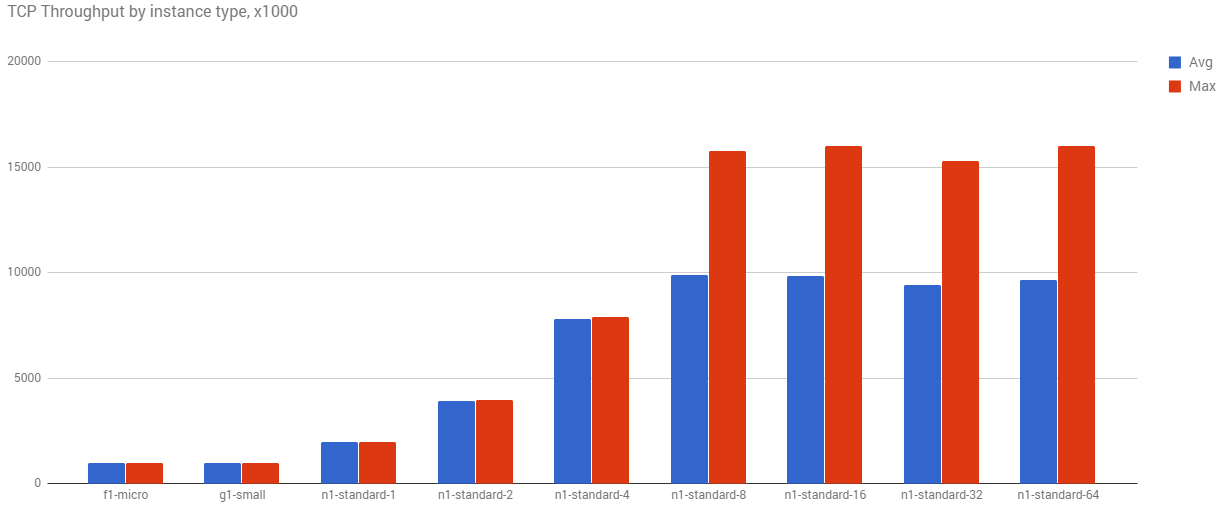
コア数が増加するにつれて、平均スループットと最大スループットは増加します。この簡単なテストでも、上位マシンに 16 Gbps という上限があることがわかります。
タスク 2. 結果の改善方法
Dobermanifesto が接続するネットワークでは 1 vCPU マシンを使用しています。コアの数を増やせば、おそらく結果は改善されるはずです。この理論を試してみましょう。
-
instance-3(4 vCPU 15 GB メモリ)に SSH 接続し、次のコマンドを実行します。
出力例:
-
instance-4(4 vCPU 15 GB メモリ)に SSH 接続します。
出力例:
- 今度は 4 つのスレッドでもう一度試してみます。
- 8 つのスレッドでも試してみます。
-
instance-3に戻り、CTRL + C を押して受信を終了します。
これらの実験では、サーバーとクライアントの両方が 4 vCPU であり、速度は大幅に向上しました。転送速度は 6.64 GB、帯域幅は 5.71 Gbit/秒の改善となり、マルチスレッドのパフォーマンスではコア数の上限に達することができました。
- 次に、
instance-5でテストを行います。これも 4 vCPU の高性能マシンで、インスタンス タイプは「highcpu-4」です。
このインスタンス タイプでは、CPU は高速ですが、メモリは少なくなっています。何か違いはありますか?マルチスレッドではどうでしょうか?
ここで、Dobermanifesto のチームはどの対策をとるか決める必要があります。CPU 使用率をプロファイルし、料金を調べた結果、e2-standard-4 マシンを使用することにしました。これにより、平均スループットはほぼ 4 倍に向上し、費用も e2-standard-8 マシンに比べて安く済みました。
大型のマシンに移行する際の利点の一つは、実際には実行頻度が少なくなることです。つまり、データを転送するだけのために、マシンが長時間待機しているということです。マシンサイズを変えることでインスタンスのダウンタイムが増えれば、ロードバランサは 1 日あたりのインスタンスの総数を減らすことができます。つまり、高性能のマシンに費用をかけることになりますが、その一方で、毎月のコアアワーを減らすことができます。
パフォーマンスが最終的な収益に直接影響を与える場合は、微妙に異なる多数のトレードオフを検討する必要があります。
ユースケース 2: 内部 IP を使用した Google Cloud ネットワーキング
次の例では、iperf を使用してスループット速度をテストします。1 基のマシンをサーバーとして設定してから、別のマシンをそのサーバーにポイントして結果を比較します。
Gecko Protocol は、B2B 企業で使用されるカスタムの軽量ネットワーキング プロトコルで、ゲームやリアルタイム グラフィック システム用に構築されています。大容量の動画やグラフィック ファイルの転送とトランスコードを行うバックエンド マシンで、スループットが予想を下回っていました。
ベースラインの iperf テストの結果は次のとおりです。
再現テストを実施したとき、ネットワーク設定は同じでしたが、テスト結果は次のようにまったく異なっていました。
1.95 GB/秒という速度は、Gecko Protocol のグラフで見られたものよりもはるかに高い数値です。何が起きているのでしょうか。
ここでこのシナリオを再作成します。
- コンソールで
instance-1に SSH 接続し、iperf 受信者を設定します。
出力例:
-
instance-2に SSH 接続し、外部 IP アドレスを使った接続を確認します。
出力例:
Gecko Protocol とさらに議論したところ、マシンの接続には外部 IP アドレスが使用され、テストでは内部 IP アドレスが使用されていたことがわかりました。マシンがネットワーク内にある場合、それらを内部 IP に接続するとスループットが向上します。
- 今度は、内部 IP アドレスを使った接続を確認します。
出力例:
両テストの転送速度と帯域幅レートが異なることに注目してください。この例では、内部 IP アドレスに変更したことで、転送速度が 0.9 GB、帯域幅が 0.78 Gbp/秒の改善となっています。つまり、内部接続のほうが速いことが証明されました。
Dobermanifesto の問題の解決策から考えると、マシンサイズを大きくすることでネットワーク速度はさらに向上するでしょうか。instance-2 の vCPU の数は 1 つです。このマシンを少し大きくすると、接続はどの程度速くなるでしょうか。さらに大きくした場合はどうでしょうか。内部 IP アドレスを使用してテストを続けます(時間がある場合は、外部 IP アドレスもテストします)。
4 基の vCPU マシン
-
instance-3に SSH 接続し、内部 IP アドレスでの接続をテストします。
出力例(実際の結果はこれとは異なる場合があります):
4 基のハイ CPU マシン
-
instance-5に SSH 接続し、内部 IP アドレスでの接続をテストします。
出力例:
このように、スループットは大幅に改善されます。
Gecko Protocol は、最適なコアサイズについても検討する必要があります。この小さなデバッグ セッションでは、動画とグラフィックのデータ転送速度が約 14 倍向上しました。同社のサービスがハイ パフォーマンス コンピューティング シナリオ向けのパフォーマンス バックエンド サービスを基に構築されていることを考えると、実際にはこれ以上の改善が見込まれる可能性があります。
タスク 3. 独自の環境でのテスト
このラボでは、受講生独自のシステムをテストする方法は扱いませんが、その際に役立つ追加の情報を以下に示します。独自のネットワークのテストについて詳しくは、Iperf を使用したネットワーク速度の診断をご覧ください。
時間があれば、VM を設定してテストすることもできます。VM を作成するときは、必ず「iperftest」ファイアウォール ルールとタグを使用してください。内部 IP アドレスと外部 IP アドレスの両方をテストします。
独自のネットワーク速度をテストするための設定
-
コンソールで、ナビゲーション メニュー > [ネットワーキング] > [VPC ネットワーク] > [ファイアウォール] の順に移動します。
-
[ファイアウォール ルールを作成] をクリックします。以下の構成を使用してファイアウォール ルールを作成します。
| フィールド | 値 | コメント |
|---|---|---|
| 名前 | iperf-testing | 新しいルールの名前 |
| ターゲット | ネットワーク上のすべてのインスタンス | |
| ソース IP の範囲 | 0.0.0.0/0 | インターネットからのすべての IP アドレスに対してファイアウォールを開きます。 |
| トラフィックの方向 | 内向き | |
| 一致したときのアクション | 許可 | |
| プロトコルとポート | tcp:5001; udp:5001 |
- [作成] をクリックします。
[進行状況を確認] をクリックして、目標に沿って進んでいることを確認します。
ワークロードをできるだけ 100% に近づけようとするため、ディスクのデフラグなどのためのスペースはほとんど残りません。
使用率が健全であれば 90~93% ですが、98% になると多くの競合が発生するため、パフォーマンスが低下します。
テスト中に IO パフォーマンスが低下した場合は、スロットル カウンタを確認します。スロットルされていない場合は、CPU 使用率を調べてください。高い場合は問題があります。
タスク 4. 時間がある場合
ラボ インターフェースの左側にある [受講者向けリソース] に、このラボに関連する動画へのリンクが記載されています。ぜひご覧ください。
![「Compute Engine and the Egress Problem」と「Internal IP vs External IP Performance」へのリンクを含む [受講者向けリソース] セクション](https://cdn.qwiklabs.com/ljTq6fUf03g%2Bi%2FX3eHU0WU0fdsT1u4myssx0gaq9KZI%3D)
お疲れさまでした
これで完了です。このラボでは、オープンソース ツールを使用してネットワークの接続とパフォーマンスをテストする方法と、マシンのサイズがネットワークのパフォーマンスにどのように影響するかについて学びました。
次のステップと詳細情報
- Google Cloud ブログ投稿「Using Google's cloud networking products: a guide to all the guides(Google のクラウド ネットワーキング サービスの使用: 全ガイドのガイド)」を読む
- Compute Engine のネットワーキングに関するドキュメントを読む
- サブネットワークについて学習する
- Stackoverflow で google-compute-engine タグまたは google-cloud-platform タグを付けて質問を投稿し、回答を得る
Google Cloud トレーニングと認定資格
Google Cloud トレーニングと認定資格を通して、Google Cloud 技術を最大限に活用できるようになります。必要な技術スキルとベスト プラクティスについて取り扱うクラスでは、学習を継続的に進めることができます。トレーニングは基礎レベルから上級レベルまであり、オンデマンド、ライブ、バーチャル参加など、多忙なスケジュールにも対応できるオプションが用意されています。認定資格を取得することで、Google Cloud テクノロジーに関するスキルと知識を証明できます。
マニュアルの最終更新日: 2023 年 10 月 4 日
ラボの最終テスト日: 2023 年 10 月 4 日
Copyright 2024 Google LLC All rights reserved. Google および Google のロゴは Google LLC の商標です。その他すべての企業名および商品名はそれぞれ各社の商標または登録商標です。