检查点
Create an API Key
/ 40
Make an Entity Analysis Request
/ 30
Check the Entity Analysis response
/ 30
使用 Natural Language API 进行实体和情感分析
GSP038

概览
通过 Cloud Natural Language API,您可以从文本中提取实体,执行情感和语法分析,以及将文本分类。
在此实验中,您将学习如何使用 Natural Language API 分析实体、情感和语法。
学习内容
- 创建 Natural Language API 请求并通过 curl 调用此 API
- 通过 Natural Language API 从文本中提取实体并进行情感分析
- 通过 Natural Language API 对文本执行语言分析
- 用其他语言创建 Natural Language API 请求
设置和要求
点击“开始实验”按钮前的注意事项
请阅读以下说明。实验是计时的,并且您无法暂停实验。计时器在您点击开始实验后即开始计时,显示 Google Cloud 资源可供您使用多长时间。
此实操实验可让您在真实的云环境中开展实验活动,免受模拟或演示环境的局限。我们会为您提供新的临时凭据,让您可以在实验规定的时间内用来登录和访问 Google Cloud。
为完成此实验,您需要:
- 能够使用标准的互联网浏览器(建议使用 Chrome 浏览器)。
- 完成实验的时间 - 请注意,实验开始后无法暂停。
如何开始实验并登录 Google Cloud 控制台
-
点击开始实验按钮。如果该实验需要付费,系统会打开一个弹出式窗口供您选择付款方式。左侧是实验详细信息面板,其中包含以下各项:
- 打开 Google 控制台按钮
- 剩余时间
- 进行该实验时必须使用的临时凭据
- 帮助您逐步完成本实验所需的其他信息(如果需要)
-
点击打开 Google 控制台。 该实验会启动资源并打开另一个标签页,显示登录页面。
提示:请将这些标签页安排在不同的窗口中,并将它们并排显示。
注意:如果您看见选择帐号对话框,请点击使用其他帐号。 -
如有必要,请从实验详细信息面板复制用户名,然后将其粘贴到登录对话框中。点击下一步。
-
请从实验详细信息面板复制密码,然后将其粘贴到欢迎对话框中。点击下一步。
重要提示:您必须使用左侧面板中的凭据。请勿使用您的 Google Cloud Skills Boost 凭据。 注意:在本次实验中使用您自己的 Google Cloud 帐号可能会产生额外费用。 -
继续在后续页面中点击以完成相应操作:
- 接受条款及条件。
- 由于该帐号为临时帐号,请勿添加帐号恢复选项或双重验证。
- 请勿注册免费试用。
片刻之后,系统会在此标签页中打开 Cloud 控制台。

任务 1. 创建 API 密钥
由于您使用 curl 向 Natural Language API 发送请求,因此必须生成要在请求网址中传递的 API 密钥。
-
要创建 API 密钥,请在 Cloud 控制台中选择导航菜单 > API 和服务 > 凭据。
-
点击创建凭据,然后选择 API 密钥。
-
复制生成的 API 密钥并点击关闭。
点击检查我的进度以验证是否完成了以下目标。
为了执行接下来的步骤,请通过 SSH 连接到为您预配的实例。
-
点击导航菜单 > Compute Engine。您应该会在虚拟机实例列表中看到预配的 linux 实例
linux-instance。 -
点击 SSH 按钮。您将转跳至一个交互式 shell。
-
在命令行中,输入以下内容,并将
<YOUR_API_KEY>替换为您刚刚复制的密钥:
任务 2. 发出实体分析请求
您使用的第一个 Natural Language API 方法是 analyzeEntities。通过此方法,API 可以从文本中提取实体(例如人物、地点和事件)。若要试用 API 的实体分析功能,请使用以下语句:
Joanne Rowling, who writes under the pen names J. K. Rowling and Robert Galbraith, is a British novelist and screenwriter who wrote the Harry Potter fantasy series.
您在 request.json 文件中构建对 Natural Language API 的请求。
- 使用 nano(一款代码编辑器)创建
request.json文件:
- 在
request.json中输入或粘贴以下代码:
- 按 CTRL+X 退出 nano,然后按 Y 保存文件,再按 ENTER 确认。
在请求中,您要告知 Natural Language API 有关所发送文本的信息。支持的类型值为 PLAIN_TEXT 或 HTML。在内容中,传递要发送给 Natural Language API 以进行分析的文本。
Natural Language API 还支持发送存储在 Cloud Storage 中的文件以进行文本处理。如果您想发送来自 Cloud Storage 的文件,请将 content 替换为 gcsContentUri,并为其赋予 Cloud Storage 中的文本文件的 URI 值。
encodingType 告知 API 在处理文本时使用哪种类型的文本编码。API 将使用它来计算特定实体是否出现在文本中。
点击检查我的进度以验证是否完成了以下目标。
任务 3. 调用 Natural Language API
- 现在,您可以通过以下
curl命令(全部包含在一个命令行中)将请求正文以及之前保存的 API 密钥环境变量传递给 Natural Language API:
- 要检查响应,请运行:
响应的开头应如下所示:
对于响应中的每个实体,您将获得实体 type(类型)、相关的维基百科网址(若有)、salience(显著性)和指示此实体在文本中出现的位置的索引。显著性是 [0,1] 范围内的一个数字,指的是相应实体对整个文本的中心性。
Natural Language API 还可识别以不同方式提及的同一实体。查看响应中的 mentions列表:API能够分辨出“Joanne Rowling”“Rowling”“novelist”和“Robert Galbriath”均指代同一个人。
点击检查我的进度以验证是否完成了以下目标。
任务 4. 通过 Natural Language API 进行情感分析
通过 Natural Language API,不仅可以提取实体,还能对一段文本执行情感分析。此 JSON 请求将包含与上一请求相同的参数,但这次我们将更改文本,使其包含的内容具有更强烈的感情。
- 使用 nano 将
request.json中的代码替换为以下代码,并将下方content随意替换为您自己的文本:
-
按 CTRL+X 退出 nano,然后按 Y 保存文件,再按 ENTER 确认。
-
接下来,向此 API 的
analyzeSentiment端点发送请求:
响应应如下所示:
注意您获得了两种类型的情感值:文档整体的情感,以及按语句细分的情感。sentiment 方法返回了两个值:
-
score(得分)- 从 -1.0 到 1.0 的数字,指示情感的积极或消极程度。 -
magnitude(量级)- 从 0 到无穷的数字,表示语句中所表达情感的权重,无论该情感是积极还是消极的。
包含高权重语句的较长文本段落具有较高的 magnitude 值。第一个语句的 score 为积极 (0.7),而第二个语句的 score 为中性 (0.1)。
任务 5. 分析实体情感
Natural Language API 不仅提供有关整个文本文档的情感详细信息,还能按文本中的实体细分情感。使用以下语句作为示例:
I liked the sushi but the service was terrible.
在本例中,像上例中那样获取整个句子的情感分数可能不怎么有用。如果这是餐厅评价,并且您有同一间餐厅的数百条评价,您会想要了解人们在评价中表明自己喜欢和不喜欢哪些确切方面。幸运的是,Natural Language API 提供了一种方法来获取文本中每个实体对应的情感,称为 analyzeEntitySentiment。我们来看看具体的操作方式。
- 使用 nano 更新
request.json,使其包含以下语句:
-
按 CTRL+X 退出 nano,然后按 Y 保存文件,再按 ENTER 确认。
-
然后使用以下 curl 命令调用
analyzeEntitySentiment端点:
在响应中,您得到了两个实体对象:“sushi”一个、“service”一个。完整的 JSON 响应如下:
可以看到,“sushi”的得分为中性的 0,而“service”的得分为 -0.7。不错!您可能还会注意到,针对每个实体返回了两个情感对象。如果这些字词中的任意一个被提及多次,该 API 将针对每次提及返回不同的情感分数和量级,以及该实体的总体情感。
任务 6. 分析语法和词性
Natural Language API 提供的另一种方法是语法分析,可用于更深入地探究文本的语言细节。analyzeSyntax 会提取语言信息,将给定文本细分为一系列语句和词元(一般是字词边界),以提供针对这些词元的进一步分析。对于文本中的每个字词,API 将告知您该字词的词性(名词、动词、形容词等)及其与语句中其他字词的关系(它是否为根动词?是否为修饰语?)。
用简单语句试一试。此 JSON 请求与以上各个请求类似,只是增加了特征键。它用于指示 API 执行语法注释。
- 使用 nano 将
request.json中的代码替换为以下内容:
-
按 CTRL+X 退出 nano,然后按 Y 保存文件,再按 ENTER 确认。
-
然后调用 API 的
analyzeSyntax方法:
对于语句中的每个词元,响应会返回如下所示的一个对象:
让我们详细看下响应的构成元素:
-
partOfSpeech表明“Joanne”是一个名词。 -
dependencyEdge包含可用于创建文本依存关系解析树的数据。本质上,这是呈现语句中字词间相互关系的图表。以上语句的依存关系解析树可能如下所示:
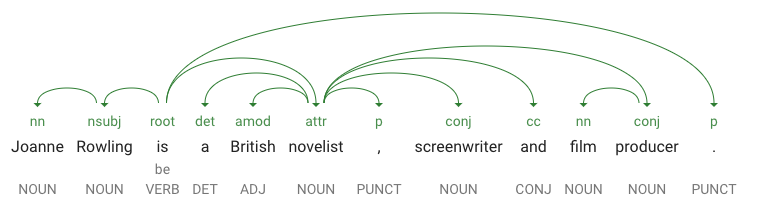
-
headTokenIndex是具有指向“Joanne”的弧的词元的索引。您可以将语句中的每个词元视为数组中的一个词。 - “Joanne”的
headTokenIndex1 表示“Rowling”,它在树中与“Joanne”相连。标签NN(代表复合名词修饰语)描述了该词在语句中的角色。“Joanne”修饰“Rowling”,即语句的主语。 -
lemma是字词的规范形式。例如,run、runs、ran 和 running 这几个动词的 lemma 均为 run。lemma 值可用于跟踪一个词在大段文字中的出现次数。
任务 7. 多语言自然语言处理
Natural Language API 还支持英语以外的语言(可在语言支持指南中找到完整列表)。
- 修改
request.json的代码,在其中添加日语语句:
- 按 CTRL+X 退出 nano,然后按 Y 保存文件,再按 ENTER 确认。
请注意,您并未告知 API 文本采用哪种语言写成,它能自动检测语言!
- 接下来,将其发送到
analyzeEntities端点:
您将获得以下响应:
维基百科网址甚至指向日语的维基百科页面,很棒!
恭喜!
您已学习如何通过 Cloud Natural Language API 提取实体、分析情感和进行语法注释,以执行文本分析。您已完成以下操作:
- 创建 Natural Language API 请求并通过 curl 调用此 API
- 通过 Natural Language API 从文本中提取实体并进行情感分析
- 对文本执行语言分析以创建依存关系解析树
- 以日语创建 Natural Language API 请求
完成挑战任务
本自学实验属于机器学习简介:语言处理和通过 Google Cloud API 进行语言、语音、文本和翻译操作挑战任务。一项挑战任务就是一系列相关的实验,学习时按部就班地完成这些实验即可。完成挑战任务即可赢得一枚徽章,以表彰您取得的成就。您可以公开展示徽章,还可以在您的在线简历或社交媒体账号中加入指向徽章的链接。欢迎注册参加任何包含此实验的挑战任务,完成后就能立即获得相应的积分。查看其他可参与的挑战任务。
参与下一项实验
尝试完成有关机器学习 API 的其他实验,例如 Vertex AI Workbench 笔记本:Qwik Start,或者尝试以下操作:
后续步骤
- 查看文档中的 Natural Language API 教程。
Google Cloud 培训和认证
…可帮助您充分利用 Google Cloud 技术。我们的课程会讲解各项技能与最佳实践,可帮助您迅速上手使用并继续学习更深入的知识。我们提供从基础到高级的全方位培训,并有点播、直播和虚拟三种方式选择,让您可以按照自己的日程安排学习时间。各项认证可以帮助您核实并证明您在 Google Cloud 技术方面的技能与专业知识。
上次更新手册的时间:2023 年 8 月 29 日
上次测试实验的时间:2023 年 8 月 29 日
版权所有 2024 Google LLC 保留所有权利。Google 和 Google 徽标是 Google LLC 的商标。其他所有公司名和产品名可能是其各自相关公司的商标。