Checkpoints
Create a cloud storage bucket
/ 25
Upload CSV files to Cloud Storage
/ 25
Create a Cloud SQL instance
/ 25
Create a database
/ 25
Introdução ao SQL para BigQuery e Cloud SQL
GSP281

Visão geral
O SQL (Structured Query Language) é uma linguagem padrão para operações de dados que permite fazer perguntas e coletar insights de conjuntos de dados estruturados. Geralmente é usado no gerenciamento de banco de dados e permite que você realize tarefas como gravação de registros de transação em bancos de dados relacionais e análise de dados em escala de petabyte.
Ele é dividido em duas partes: na primeira, você vai aprender as principais palavras-chave para consultas SQL e executá-las no BigQuery, em um conjunto de dados público com informações sobre o compartilhamento de bicicletas em Londres.
Na segunda parte, você vai aprender a exportar subconjuntos desse conjunto de dados para arquivos CSV e fazer upload no Cloud SQL. Depois você vai aprender a usar o Cloud SQL para criar e gerenciar bancos de dados e tabelas. Por último, você vai fazer uma atividade prática com outras palavras-chave SQL para manipular e editar dados.
O que você vai aprender
Neste laboratório, você vai aprender a:
- Carregar bancos de dados e tabelas no BigQuery.
- Executar consultas simples em tabelas para receber informações significativas dos conjuntos de dados.
- Exportar um subconjunto de dados para um arquivo CSV e armazenar esse arquivo em um novo bucket do Cloud Storage.
- Criar uma nova instância do Cloud SQL e carregar seu arquivo CSV exportado como uma nova tabela.
Pré-requisitos
Importante: antes de começar este laboratório, saia da sua conta pessoal ou corporativa do Gmail.
Este é um laboratório de nível introdutório. Ele é indicado para quem tem pouca ou nenhuma experiência com o SQL. Recomendamos que o participante tenha experiência com o Cloud Storage e o Cloud Shell, mas isso não é obrigatório. Neste laboratório, você vai aprender as noções básicas de leitura e gravação de consultas no SQL. Em seguida, vai aplicá-las usando o BigQuery e o Cloud SQL.
Antes de começar este laboratório, analise sua proficiência em SQL. Veja abaixo alguns laboratórios mais complexos em que você pode aplicar seu conhecimento a casos de uso mais avançados:
Quando estiver pronto, role a tela para baixo e execute as etapas a seguir para configurar seu ambiente de laboratório.
Configuração e requisitos
Antes de clicar no botão Start Lab
Leia estas instruções. Os laboratórios são cronometrados e não podem ser pausados. O timer é iniciado quando você clica em Começar o laboratório e mostra por quanto tempo os recursos do Google Cloud vão ficar disponíveis.
Este laboratório prático permite que você realize as atividades em um ambiente real de nuvem, não em uma simulação ou demonstração. Você vai receber novas credenciais temporárias para fazer login e acessar o Google Cloud durante o laboratório.
Confira os requisitos para concluir o laboratório:
- Acesso a um navegador de Internet padrão (recomendamos o Chrome).
- Tempo para concluir o laboratório---não se esqueça: depois de começar, não será possível pausar o laboratório.
Como iniciar seu laboratório e fazer login no console do Google Cloud
-
Clique no botão Começar o laboratório. Se for preciso pagar, você verá um pop-up para selecionar a forma de pagamento. No painel Detalhes do laboratório à esquerda, você verá o seguinte:
- O botão Abrir Console do Cloud
- Tempo restante
- As credenciais temporárias que você vai usar neste laboratório
- Outras informações se forem necessárias
-
Clique em Abrir Console do Google. O laboratório ativa recursos e depois abre outra guia com a página Fazer login.
Dica: coloque as guias em janelas separadas lado a lado.
Observação: se aparecer a caixa de diálogo Escolher uma conta, clique em Usar outra conta. -
Caso seja preciso, copie o Nome de usuário no painel Detalhes do laboratório e cole esse nome na caixa de diálogo Fazer login. Clique em Avançar.
-
Copie a Senha no painel Detalhes do laboratório e a cole na caixa de diálogo Olá. Clique em Avançar.
Importante: você precisa usar as credenciais do painel à esquerda. Não use suas credenciais do Google Cloud Ensina. Observação: se você usar sua própria conta do Google Cloud neste laboratório, é possível que receba cobranças adicionais. -
Acesse as próximas páginas:
- Aceite os Termos e Condições.
- Não adicione opções de recuperação nem autenticação de dois fatores (porque essa é uma conta temporária).
- Não se inscreva em testes gratuitos.
Depois de alguns instantes, o console do GCP vai ser aberto nesta guia.

Tarefa 1: noções básicas de SQL
Bancos de dados e tabelas
Como mencionado anteriormente, o SQL permite coletar informações de “conjuntos de dados estruturados”, que têm regras e formatação claras e, muitas vezes, são organizados em tabelas ou dados formatados em linhas e colunas.
Um exemplo de dados não estruturados é um arquivo de imagem. Dados não estruturados não são processados no SQL nem podem ser armazenados em conjuntos de dados ou tabelas do BigQuery (pelo menos de forma nativa). Para trabalhar com dados de imagem, por exemplo, você pode usar um serviço como o Cloud Vision, talvez diretamente na API.
Veja a seguir um exemplo de um conjunto de dados estruturado, na forma de uma tabela simples:
|
User |
Price |
Shipped |
|
Sean |
$35 |
Yes |
|
Rocky |
$50 |
No |
Os itens acima parecerão familiares caso você já tenha usado o Planilhas Google. A tabela tem as colunas "User", "Price" e "Shipped" e duas linhas compostas de valores de coluna preenchidos.
Um banco de dados é basicamente um conjunto de uma ou mais tabelas. O SQL é uma ferramenta de gerenciamento de banco de dados estruturados, mas, na maioria das vezes e também neste laboratório, você executará consultas em uma ou mais tabelas unidas, não em bancos de dados inteiros.
SELECT e FROM
A linguagem SQL é fonética por natureza e, antes de executar uma consulta, é sempre útil descobrir qual pergunta você quer fazer aos dados, a menos que você esteja explorando apenas por diversão.
O SQL tem palavras-chave predefinidas que são usadas para traduzir sua pergunta para a sintaxe SQL em pseudoinglês, de forma que o mecanismo do banco de dados retorne a resposta desejada.
As palavras-chave mais importantes são SELECT e FROM:
- Use
SELECTpara especificar quais campos você quer extrair do seu conjunto de dados. - Use
FROMpara especificar de quais tabelas você quer extrair dados.
Confira a seguir um exemplo para entender melhor. Suponha que você tenha a seguinte tabela example_table com as colunas USER, PRICE e SHIPPED:
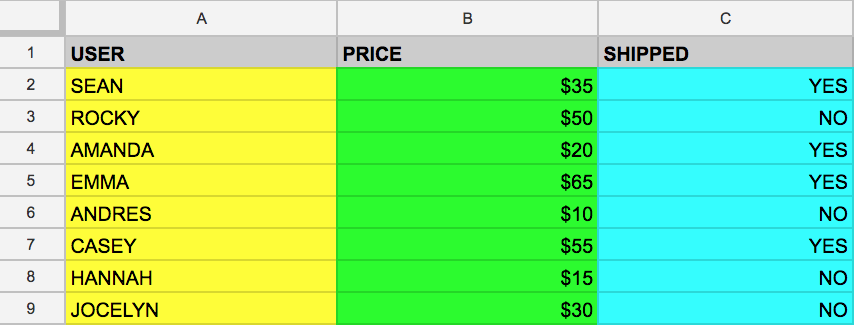
Você quer extrair apenas os dados da coluna USER. Para isso, você executa a seguinte consulta, que usa SELECT e FROM:
Ao executar o comando acima, você seleciona todos os nomes da coluna USER que são encontrados em example_table.
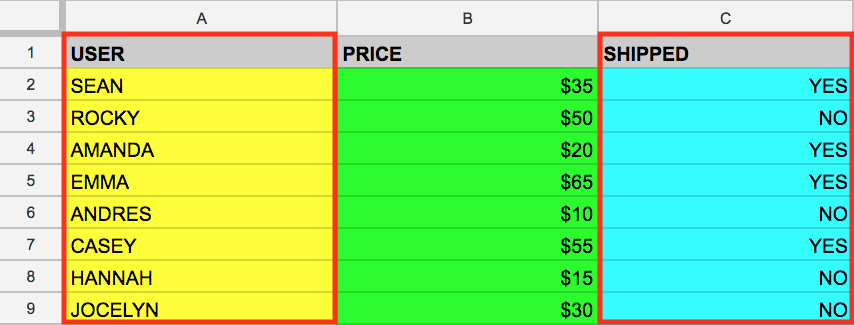
Você também pode selecionar várias colunas com a palavra-chave SQL SELECT. Digamos que você queira extrair os dados encontrados nas colunas USER e SHIPPED. Para fazer isso, modifique a consulta anterior adicionando outro valor de coluna à consulta SELECT. Lembre-se de separar esses valores por vírgula:
Essa consulta recupera os dados de USER e SHIPPED da memória:
Agora que você já conhece as duas palavras-chave SQL mais importantes, as coisas ficarão mais interessantes.
WHERE
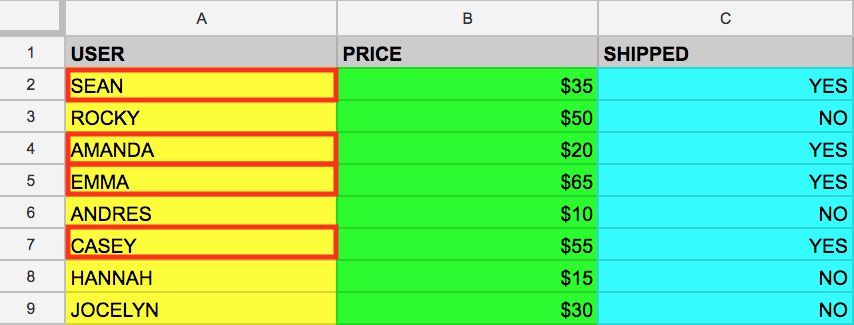
A palavra-chave WHERE é outro comando SQL que filtra valores de coluna específicos nas tabelas. Digamos que você queira extrair os nomes dos usuários que já tiveram pacotes enviados da tabela example_table. Você pode complementar a consulta com WHERE, como neste exemplo:
A consulta acima retorna todos os nomes de USERS que tiveram pacotes SHIPPED da memória:
Agora que você conhece as principais palavras-chave do SQL, aplique o que aprendeu executando consultas desse tipo no console do BigQuery.
Teste seu conhecimento
Responda às perguntas de múltipla escolha a seguir para reforçar sua compreensão dos conceitos abordados até agora. Use tudo o que você aprendeu até aqui.
Tarefa 2: conheça o console do BigQuery
O paradigma do BigQuery
O BigQuery é um data warehouse totalmente gerenciado em escala de petabytes executado no Google Cloud. Os analistas e cientistas de dados podem fazer consultas e filtrar grandes conjuntos de dados rapidamente, agregar resultados e realizar operações complexas sem se preocupar com a configuração e o gerenciamento de servidores. É possível usar o BigQuery como uma ferramenta de linha de comando (pré-instalada no Cloud Shell) ou um console da Web. As duas opções estão prontas para gerenciar e consultar dados armazenados em projetos do Google Cloud.
Neste laboratório, você vai usar o console da Web para executar consultas SQL.
Abrir o console do BigQuery
- No Console do Google Cloud, selecione o menu de navegação > BigQuery:
Você verá a caixa de mensagem Olá! Este é o BigQuery no Console do Cloud. Ela tem um link para o guia de início rápido e as notas de versão.
- Clique em OK.
O console do BigQuery vai abrir.
Reserve um tempo para observar alguns recursos importantes da interface. No lado direito do console, está o Editor de consultas. Nele, é possível escrever e executar comandos SQL como os exemplos já mencionados. Abaixo vemos o "Query history", que é uma lista das consultas já feitas.
No painel esquerdo do console, está o menu de navegação. Além do histórico de consultas, das consultas salvas e do histórico de jobs, que são autoexplicativos, existe a guia Explorer.
O nível mais alto de recursos na guia Explorer contém projetos do Google Cloud, que são como os projetos temporários do Google Cloud em que você faz login e usa em cada laboratório do Google Cloud Ensina. Como é possível notar no console e na última captura de tela, o projeto está apenas na guia "Explorer". Dessa forma, nada vai acontecer se você clicar na seta ao lado do nome do projeto.
O motivo disso é que seu projeto não tem conjuntos de dados nem tabelas, ou seja, não há nada que possa ser consultado. Anteriormente, você aprendeu que os conjuntos de dados contêm tabelas. Quando você adicionar dados ao seu projeto, lembre-se: no BigQuery, ele terá conjuntos de dados e esses conjuntos terão tabelas. Agora que você entende melhor o paradigma projeto > conjunto de dados > tabela e conhece os detalhes do console, é hora de carregar alguns dados consultáveis.
Como fazer upload de dados para consulta
Nesta seção, você vai adicionar alguns dados públicos ao seu projeto para praticar a execução de comandos SQL no BigQuery.
-
Clique em + ADICIONAR.
-
Escolha Marcar um projeto com estrela por nome.
-
Insira o nome do projeto como bigquery-public-data.
-
Clique em MARCAR COM ESTRELA.
É importante observar que você ainda vai estar trabalhando no projeto do laboratório nessa nova guia. Você não trocou de projeto, apenas adicionou um projeto de acesso público, que contém conjuntos de dados e tabelas, ao BigQuery para análise. Seus jobs e serviços ainda estão vinculados à conta do Google Cloud Ensina. Confira isso verificando o campo do projeto na parte superior do console:
- Agora, você tem acesso aos seguintes dados:
- Projeto do Google Cloud →
bigquery-public-data - Conjunto de dados →
london_bicycles
- Clique no conjunto de dados london bicycles para ver as tabelas associadas
- Tabela →
cycle_hire - Tabela →
cycle_stations
Neste laboratório, você vai usar os dados de cycle_hire. Abra a tabela cycle_hire e clique na guia Visualizar. Sua página deve se parecer com esta:
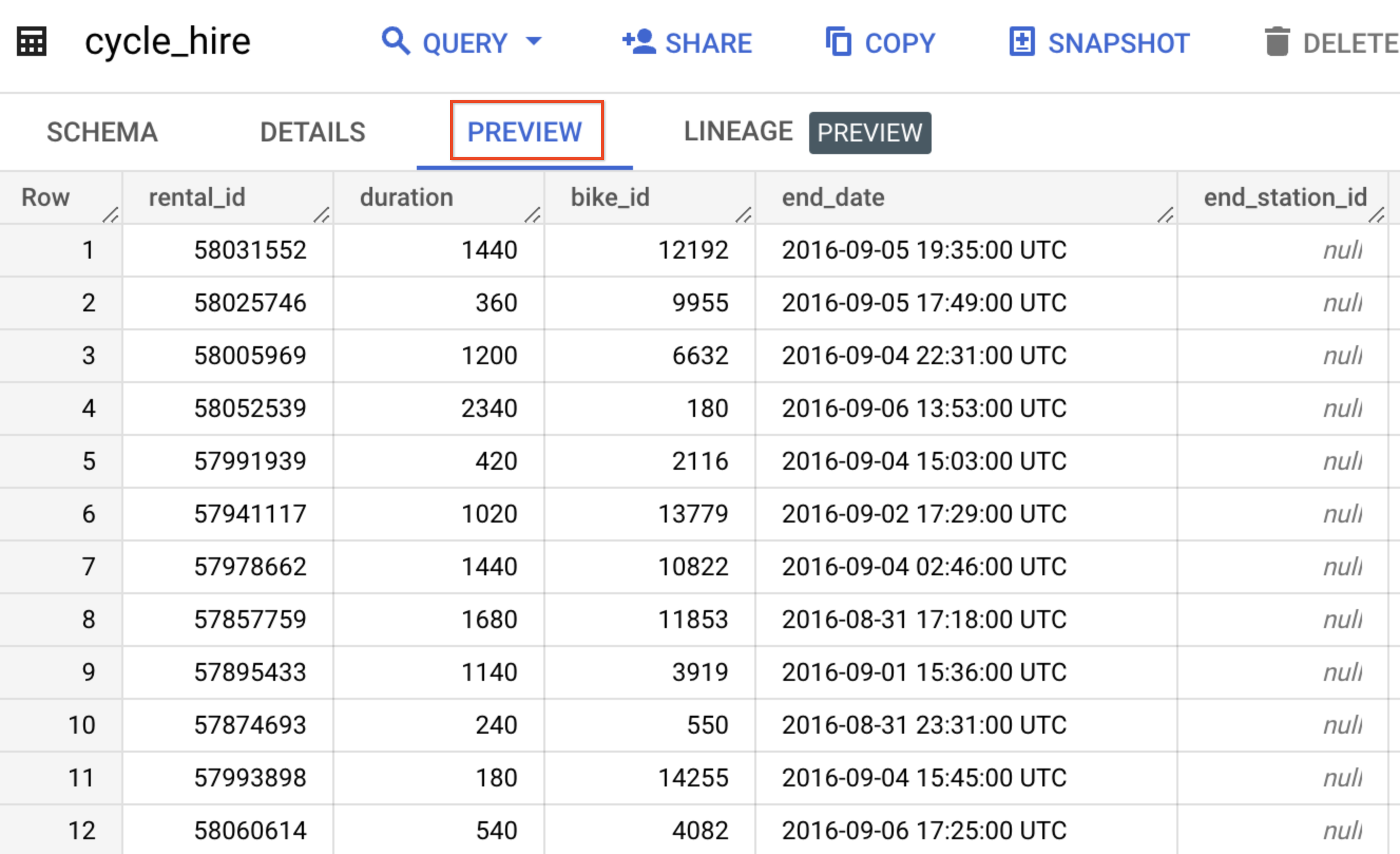
Analise as colunas e os valores preenchidos nas linhas. Você já pode executar algumas consultas SQL na tabela cycle_hire.
Execute SELECT, FROM e WHERE no BigQuery
Agora que você já tem uma compreensão básica das palavras-chave de consulta SQL, do paradigma de dados do BigQuery e alguns dados para trabalhar, execute alguns comandos SQL usando este serviço.
Se você olhar no canto inferior direito do console, verá que há 24.369.201 linhas de dados, que representam o número de viagens de bicicletas compartilhadas em Londres entre 2015 e 2017. Bastante, não é?
Agora, confira a chave da sétima coluna: end_station_name, que especifica o destino final dos passeios de bicicletas compartilhadas. Antes de se aprofundar, execute uma consulta simples para isolar a coluna end_station_name.
- Copie e cole o seguinte comando no Editor de consultas:
- Depois, clique em Executar.
Após cerca de 20 segundos, serão retornadas 24.369.201 linhas que incluem a coluna que consultamos: end_station_name.
Descubra agora quantas viagens de bicicleta duraram 20 minutos ou mais.
- Limpe a consulta do Editor e execute esta consulta, que usa a palavra-chave
WHERE:
Essa consulta pode levar mais ou menos um minuto para ser executada.
SELECT * retorna todos os valores da coluna da tabela. A duração é medida em segundos. Por isso, foi usado o valor 1.200 (60 * 20).
Você verá no canto inferior direito que 7.334.890 linhas foram retornadas. Como uma fração do total (7.334.890/24.369.201), isso significa que cerca de 30% dos passeios de bicicleta em Londres duraram 20 minutos ou mais. Pedalaram bastante!
Teste seu conhecimento
Responda às perguntas de múltipla escolha a seguir para reforçar sua compreensão dos conceitos que abordamos até agora. Use tudo o que você aprendeu até aqui.
Tarefa 3: mais palavras-chave SQL: GROUP BY, COUNT, AS e ORDER BY
GROUP BY
A palavra-chave GROUP BY agregará linhas do conjunto de resultados que compartilham critérios comuns (por exemplo, um valor de coluna) e retornará todas as entradas exclusivas encontradas para tais critérios.
Essa palavra-chave é útil para descobrir informações categóricas em tabelas.
- Para entender melhor o que ela faz, limpe a consulta do Editor e depois copie e cole este comando:
- Clique em Executar.
Seus resultados formam uma lista de valores de coluna exclusivos (não duplicados).
Sem a palavra-chave GROUP BY, a consulta teria retornado todas as 24.369.201 linhas. GROUP BY retorna os valores de coluna exclusivos encontrados na tabela. Para confirmar isso, olhe para o canto inferior direito. Você verá 880 linhas, o que significa que há 880 pontos de partida de bicicletas compartilhadas em Londres.
COUNT
A função COUNT() retornará o número de linhas que compartilham os mesmos critérios (por exemplo, valor da coluna). Usá-la junto com a palavra-chave GROUP BY pode ser muito útil.
Adicione a função COUNT à consulta anterior para descobrir quantos passeios começam em cada ponto de partida.
- Limpe a consulta do editor, copie e cole o seguinte comando e clique em Executar:
A saída mostra quantos passeios de bicicletas começam em cada ponto de partida.
AS
O SQL também tem a palavra-chave AS, que cria um alias de uma tabela ou coluna. Um alias é um novo nome dado à coluna ou tabela retornada, dependendo do AS especificado.
- Adicione a palavra-chave
ASà última consulta executada para conferir o processo. Limpe a consulta do Editor e depois copie e cole este comando:
- Clique em Executar.
Em "Resultados", o nome da coluna à direita muda de COUNT(*) para num_starts.
Veja que a coluna COUNT(*) na tabela retornada foi definida com o nome do alias num_starts. Essa é uma palavra-chave que pode ser usada principalmente no trabalho com grandes conjuntos de dados, já que um nome de tabela ou coluna ambíguo é mais frequente do que você imagina.
ORDER BY
A palavra-chave ORDER BY classifica os dados retornados de uma consulta em ordem crescente ou decrescente com base em um critério ou valor de coluna especificados. Adicione essa palavra-chave à consulta anterior para fazer o seguinte:
- retornar uma tabela com o número de passeios de bicicleta que começam em cada estação inicial, com os nomes das estações organizados em ordem alfabética;
- retornar uma tabela com o número de passeios de bicicleta que começam em cada estação inicial, organizados numericamente do menor para o maior;
- retornar uma tabela com o número de passeios de bicicleta que começam em cada estação inicial, organizados numericamente do maior para o menor.
Cada um dos comandos abaixo é uma consulta separada. Para cada comando, faça o seguinte:
- Limpe o Editor de consultas.
- Copie e cole o comando no Editor de consultas.
- Clique em Executar. Veja os resultados.
Os resultados da última consulta listam os locais de início pelo número de passeios que partem desse local.
Observe que "Belgrove Street, King's Cross" tem o maior número de partidas. No entanto, como uma fração do total (234.458/24.369.201), é possível notar que menos de 1% das partidas ocorrem nessa estação.
Teste seu conhecimento
Responda às perguntas de múltipla escolha a seguir para reforçar sua compreensão dos conceitos abordados até agora. Use tudo o que você aprendeu até aqui.
Tarefa 4: trabalhe com o Cloud SQL
Exporte consultas como arquivos CSV
O Cloud SQL é um serviço de banco de dados totalmente gerenciado que facilita a configuração, a manutenção, o gerenciamento e a administração dos seus bancos de dados relacionais PostgreSQL e MySQL na nuvem. Existem dois formatos de dados aceitos pelo Cloud SQL: arquivos dump (.sql) ou arquivos CSV (.csv). Você vai aprender a exportar subconjuntos da tabela cycle_hire para arquivos CSV e fazer upload para o Cloud Storage como um local intermediário.
De volta ao console do BigQuery, este foi o último comando que você executou:
-
Na seção "Query results", clique em SALVAR RESULTADOS > CSV (arquivo local). A consulta é salva localmente em um arquivo CSV. Anote o local e o nome desse arquivo porque você vai precisar dele em breve.
-
Limpe o Editor de consultas, depois copie e execute o seguinte comando nele:
Essa consulta retorna uma tabela com o número de passeios de bicicleta que terminam em cada estação final, classificada do número mais alto para o mais baixo.
- Na seção "Query results", clique em SALVAR RESULTADOS > CSV (arquivo local). A consulta é salva localmente em um arquivo CSV. Anote o local e o nome desse arquivo porque você precisará dele na próxima seção.
Faça upload dos arquivos CSV para o Cloud Storage
-
Acesse o console do Cloud, onde você vai criar um bucket de armazenamento para fazer upload dos arquivos que acabou de criar.
-
Selecione Menu de navegação > Cloud Storage > Buckets e clique em CRIAR BUCKET.
-
Insira um nome exclusivo para o bucket, mantenha todas as outras configurações como padrão e clique em Criar.
-
Se for solicitado, clique em Confirmar na caixa de diálogo
O acesso público será bloqueado.
Teste a tarefa concluída
Clique em Verificar meu progresso abaixo para conferir seu andamento no laboratório. Se você tiver concluído a criação do bucket, verá uma pontuação de avaliação.
Agora você deve estar no console do Cloud, vendo seu bucket do Cloud Storage recém-criado.
-
Clique em FAZER UPLOAD DE ARQUIVOS e selecione o CSV que contém os dados de
start_station_name. -
Em seguida, clique em Abrir. Repita essa etapa com os dados de
end_station_name. -
Dê um novo nome ao arquivo
start_station_nameclicando nos três pontos ao lado dele e em Renomear. Mude o nome parastart_station_data.csv. -
Clique nos três pontos ao lado do arquivo
end_station_namee em Renomear para mudar o nome. Mude o nome do arquivo paraend_station_data.csv.
Agora, start_station_data.csv e end_station_data.csv devem estar na lista Objetos da página Detalhes do bucket.
Teste a tarefa concluída
Clique em Verificar meu progresso para conferir a tarefa realizada. Se você tiver feito upload dos objetos CSV para o bucket corretamente, receberá uma pontuação de avaliação.
Tarefa 5: crie uma instância do Cloud SQL
No console, selecione Menu de navegação > SQL.
-
Clique em CRIAR INSTÂNCIA > Escolha MySQL .
-
Insira o ID da instância como my-demo.
-
Digite uma senha forte no campo Senha (e anote!).
-
Selecione a versão do banco de dados MySQL 8.
-
Em Escolher uma edição do Cloud SQL, selecione Enterprise.
-
Em Predefinição, selecione Desenvolvimento (4 vCPU, 16 GB de RAM, 100 GB de armazenamento, zona única).
-
Defina o campo Várias zonas (altamente disponíveis) como
-
Clique em CRIAR INSTÂNCIA.
- Clique na instância do Cloud SQL. A página Visão geral do SQL é aberta.
Teste a tarefa concluída
Para ver seu progresso neste laboratório, clique em Verificar meu progresso abaixo. Se a instância do Cloud SQL tiver sido configurada corretamente, você receberá uma pontuação de avaliação.
Tarefa 6: novas consultas no Cloud SQL
Palavra-chave CREATE (bancos de dados e tabelas)
Agora que a instância do Cloud SQL está funcionando, use a linha de comando do Cloud Shell para criar um banco de dados dentro dela.
-
Abra o Cloud Shell clicando no ícone no canto superior direito do console.
-
Execute o seguinte comando para definir o ID do projeto como uma variável de ambiente:
Crie um banco de dados no Cloud Shell
- Execute o seguinte comando no Cloud Shell para configurar a autenticação sem abrir um navegador.
Essa ação vai fornecer um link para ser aberto no navegador. Abra o link no mesmo navegador que você está usando para acessar a conta do qwiklabs. Após o login, você vai receber um código de verificação para copiar. Cole esse código no Cloud Shell.
- Execute o seguinte comando para se conectar à sua instância do SQL, substituindo
my-democaso você tenha usado um nome diferente para sua instância:
- Quando solicitado, digite a senha raiz que você definiu para ela.
Você vai ver uma saída semelhante:
Uma instância do Cloud SQL acompanha bancos de dados pré-configurados, mas você vai criar os próprios bancos de dados para armazenar os dados de compartilhamento de bicicletas de Londres.
- Execute o seguinte comando no prompt do servidor do MySQL para criar um banco de dados chamado
bike:
Você receberá a seguinte saída:
Teste a tarefa concluída
Clique em Verificar meu progresso para analisar a tarefa realizada. Se você tiver criado corretamente um banco de dados na instância do Cloud SQL, vai receber uma pontuação de avaliação.
Criar uma tabela no in Cloud Shell
- Crie uma tabela dentro do banco de dados de bicicletas executando o seguinte comando:
Essa instrução usa a palavra-chave CREATE, mas, desta vez, usamos a cláusula TABLE para especificar que queremos criar uma tabela em vez de um banco de dados. A palavra-chave USE especifica o banco de dados que você quer usar. Agora você tem uma tabela chamada “london1” que contém duas colunas: “start_station_name” e “num”. VARCHAR(255) especifica uma coluna de string de comprimento variável que pode conter até 255 caracteres. Já INT é uma coluna com o tipo de valores inteiros.
- Crie outra tabela chamada “london2” executando este comando:
- Agora verifique se as tabelas vazias foram criadas. Execute estes comandos no prompt do servidor do MySQL:
Você vai receber a seguinte saída para os dois comandos:
Você vai ver "empty set" porque ainda não carregou os dados.
Faça upload de arquivos CSV para tabelas
Volte para o console do Cloud SQL. Nele, você fará upload dos arquivos CSV start_station_name e end_station_name para as tabelas "london1" e "london2" que acabou de criar.
- Na página da instância do Cloud SQL, clique em IMPORTAR.
- No campo do arquivo do Cloud Storage, clique em Procurar e, na seta ao lado do nome do bucket, selecione
start_station_data.csv. Clique em Selecionar. - Selecione CSV como formato de arquivo.
- Selecione o banco de dados
bikee digitelondon1como a tabela. - Clique em Importar.
Faça o mesmo para o outro arquivo CSV.
- Na página da instância do Cloud SQL, clique em IMPORTAR.
- No campo do arquivo do Cloud Storage, clique em Procurar e, na seta ao lado do nome do bucket, selecione
end_station_data.csv. Clique em Selecionar. - Selecione CSV como formato de arquivo.
- Selecione o banco de dados "bike" e digite
london2como a tabela. - Clique em Importar.
Agora os dois arquivos CSV já foram enviados para as tabelas no banco de dados bike.
- Retorne à sua sessão do Cloud Shell e execute o comando abaixo no comando do servidor do MySQL para verificar o conteúdo de “london1”:
Você vai receber 955 linhas de saída, uma para cada nome de estação.
- Execute este comando para verificar se a tabela “london2” foi preenchida:
Você vai receber 959 linhas de saída, uma para cada nome de estação.
Palavra-chave DELETE
Agora veja mais algumas palavras-chave SQL que ajudam no gerenciamento de dados. A primeira é a palavra-chave DELETE.
- Execute os seguintes comandos na sua sessão do MySQL para excluir a primeira linha das tabelas “london1” e “london2”:
Você vai receber a seguinte saída depois de executar os dois comandos:
Os títulos das colunas foram excluídos dos arquivos CSV. A palavra-chave DELETE não removerá a primeira linha do arquivo, mas todas as linhas da tabela em que o nome da coluna (neste caso, "num") contém um valor (neste caso, "0") serão removidas. Se você executar as consultas SELECT * FROM london1; e SELECT * FROM london2; e rolar até o topo da tabela, verá que essas linhas não existem mais.
Palavra-chave INSERT INTO
Também é possível inserir valores em tabelas com a palavra-chave INSERT INTO.
- Execute o comando a seguir para inserir uma nova linha em "london1", que define
start_station_namecomo "destino teste" enumcomo "1":
A palavra-chave INSERT INTO exige uma tabela (london1) e vai criar uma linha com as colunas especificadas por termos no primeiro parêntese (neste caso, "start_station_name" e "num"). Os valores incluídos depois da cláusula “VALUES” serão inseridos na nova linha.
Você receberá a seguinte saída:
Se você executar a consulta SELECT * FROM london1;, outra linha será adicionada à parte inferior da tabela “london1”.
Palavra-chave UNION
A última palavra-chave SQL que você vai aprender é UNION. Essa palavra-chave combina a saída de duas ou mais consultas SELECT em um conjunto de resultados. Use UNION para agrupar subconjuntos das tabelas "london1" e "london2".
A consulta encadeada a seguir coleta dados específicos das duas tabelas e os combina com o operador UNION.
- Execute este comando no prompt do servidor do MySQL:
A primeira consulta SELECT seleciona as duas colunas da tabela “london1” e cria um alias para “start_station_name”, que é definido como “top_stations”. Ela usa a palavra-chave WHERE para extrair apenas os nomes das estações de compartilhamento de bicicletas onde tenham ocorrido mais de 100 mil partidas.
A segunda consulta SELECT seleciona as duas colunas da tabela “london2” e usa a palavra-chave WHERE para extrair apenas os nomes das estações de compartilhamento de bicicleta onde tenham ocorrido mais de 100 mil chegadas.
A palavra-chave intermediária UNION combina a saída dessas consultas, juntando os dados de "london2" e "london1". Como "london1" será unificada com "london2", os valores das colunas que prevalecerão serão "top_stations" e "num".
ORDER BY ordenará a tabela final unificada pelo valor da coluna "top_stations" em ordem alfabética e decrescente.
Você receberá a seguinte saída:
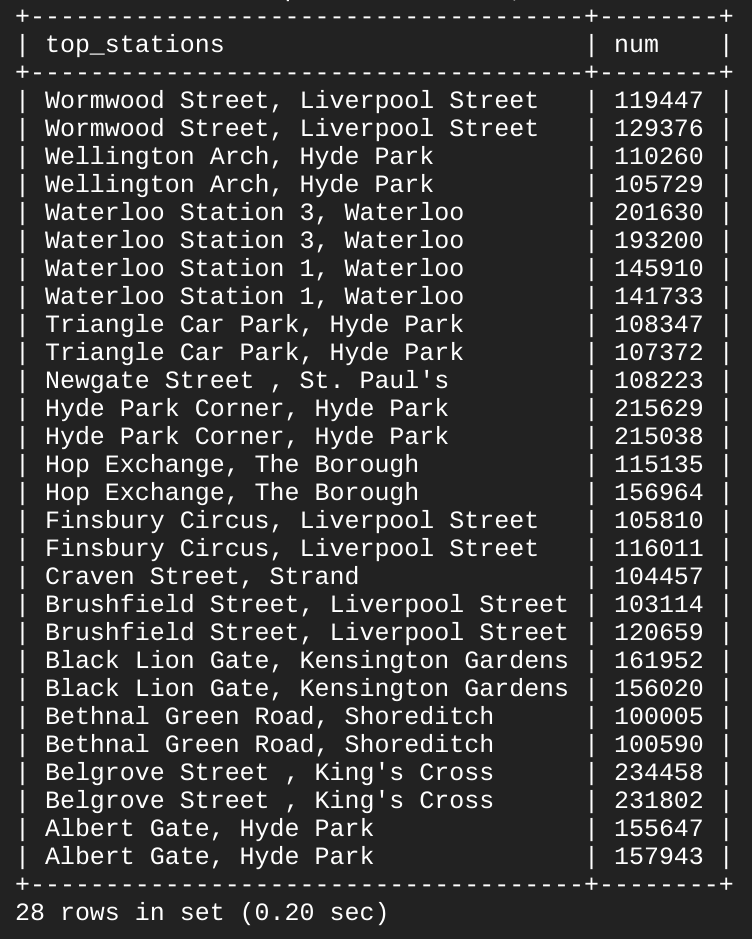
Como podemos ver, 13 das 14 estações estão em primeiro lugar em termos de número de partidas e de chegadas. Com algumas palavras-chave SQL básicas, foi possível consultar um conjunto de dados considerável, que retornou pontos de dados e respostas a perguntas específicas.
Parabéns!
Neste laboratório, você aprendeu os princípios básicos do SQL e como aplicar palavras-chave e executar consultas no BigQuery e no Cloud SQL. Você aprendeu os principais conceitos por trás de projetos, bancos de dados e tabelas, além de concluir atividades práticas com palavras-chave que manipulam e editam dados. Também mostramos como carregar conjuntos de dados no BigQuery e como executar consultas em tabelas. Você também aprendeu a criar instâncias no Cloud SQL, praticou como transferir subconjuntos de dados para tabelas inclusas em bancos de dados e encadeou e executou consultas no Cloud SQL para chegar a conclusões interessantes sobre as estações de partida e chegada de compartilhamento de bicicletas em Londres.
Termine a Quest
Este laboratório autoguiado faz parte das Quests Data Science on Google Cloud, Cloud SQL, BigQuery Basics for Data Analysts, NCAA® March Madness®: Bracketology with Google Cloud, Cloud Engineering, Data Catalog Fundamentals e Applying BQML's Classification, Regression, and Demand Forecasting for Retail Applications. Uma Quest é uma série de laboratórios relacionados que formam um programa de aprendizado. Ao concluir uma Quest, você ganha um selo como reconhecimento da sua conquista. É possível publicar os selos e incluir um link para eles no seu currículo on-line ou nas redes sociais. Inscreva-se em qualquer Quest que tenha este laboratório para receber os créditos de conclusão na mesma hora. Confira o catálogo do Google Cloud Ensina para ver todas as Quests disponíveis.
Próximas etapas/Saiba mais
Continue a aprender e praticar com o Cloud SQL e o BigQuery usando estes laboratórios do Google Cloud Ensina:
- Dados meteorológicos no BigQuery
- Explorar dados da NCAA com o BigQuery
- Como carregar dados no Google Cloud SQL
- Cloud SQL com Terraform
Saiba mais sobre ciência de dados com Data Science on the Google Cloud Platform, 2nd Edition: O'Reilly Media, Inc..
Treinamento e certificação do Google Cloud
Esses treinamentos ajudam você a aproveitar as tecnologias do Google Cloud ao máximo. Nossas aulas incluem habilidades técnicas e práticas recomendadas para ajudar você a alcançar rapidamente o nível esperado e continuar sua jornada de aprendizado. Oferecemos treinamentos que vão do nível básico ao avançado, com opções de aulas virtuais, sob demanda e por meio de transmissões ao vivo para que você possa encaixá-las na correria do seu dia a dia. As certificações validam sua experiência e comprovam suas habilidades com as tecnologias do Google Cloud.
Manual atualizado em 16 de janeiro de 2024
Laboratório testado em 6 de outubro de 2023
Copyright 2024 Google LLC. Todos os direitos reservados. Google e o logotipo do Google são marcas registradas da Google LLC. Todos os outros nomes de produtos e empresas podem ser marcas registradas das respectivas empresas a que estão associados.