Points de contrôle
Disable and re-enable the Dataflow API
/ 10
Create a Cloud Storage Bucket
/ 10
Copy Files to Your Bucket
/ 10
Create the BigQuery Dataset (name: lake)
/ 20
Build a Data Ingestion Dataflow Pipeline
/ 10
Build a Data Transformation Dataflow Pipeline
/ 10
Build a Data Enrichment Dataflow Pipeline
/ 10
Build a Data lake to Mart Dataflow Pipeline
/ 20
Traitement ETL sur Google Cloud avec Dataflow et BigQuery (Python)
- GSP290
- Présentation
- Préparation
- Tâche 1 : Vérifier que l'API Dataflow est activée
- Tâche 2 : Télécharger le code de démarrage
- Tâche 3 : Créer un bucket Cloud Storage
- Tâche 4 : Copier des fichiers dans votre bucket
- Tâche 5 : Créer l'ensemble de données BigQuery "lake"
- Tâche 6 : Créer un pipeline Dataflow
- Tâche 7 : Ingestion de données avec un pipeline Dataflow
- Tâche 8 : Examiner le code Python du pipeline
- Tâche 9 : Exécuter le pipeline Apache Beam
- Tâche 10 : Transformation des données
- Tâche 11 : Exécuter le pipeline de transformation Dataflow
- Tâche 12 : Enrichissement des données
- Tâche 13 : Examiner le code Python du pipeline d'enrichissement de données
- Tâche 14 : Exécuter le pipeline Dataflow d'enrichissement de données
- Tâche 15 : Créer un pipeline entre le lac de données et un magasin et examiner le code Python du pipeline
- Tâche 16 : Exécuter le pipeline Apache Beam pour associer les données et créer la table qui en résulte dans BigQuery
- Tester vos connaissances
- Félicitations !
GSP290

Présentation
Dans cet atelier, vous allez créer plusieurs pipelines afin d'ingérer dans BigQuery des données provenant d'un ensemble de données public à l'aide des services Google Cloud suivants :
- Cloud Storage
- Dataflow
- BigQuery
Vous allez créer votre propre pipeline de données, en arrêtant des choix en matière de conception et d'implémentation pour garantir la conformité de votre prototype aux exigences. Pensez à ouvrir les fichiers Python et à bien lire les commentaires lorsque vous y êtes invité.
Préparation
Avant de cliquer sur le bouton "Démarrer l'atelier"
Lisez ces instructions. Les ateliers sont minutés, et vous ne pouvez pas les mettre en pause. Le minuteur, qui démarre lorsque vous cliquez sur Démarrer l'atelier, indique combien de temps les ressources Google Cloud resteront accessibles.
Cet atelier pratique vous permet de suivre vous-même les activités dans un véritable environnement cloud, et non dans un environnement de simulation ou de démonstration. Nous vous fournissons des identifiants temporaires pour vous connecter à Google Cloud le temps de l'atelier.
Pour réaliser cet atelier :
- vous devez avoir accès à un navigateur Internet standard (nous vous recommandons d'utiliser Chrome) ;
- vous disposez d'un temps limité ; une fois l'atelier commencé, vous ne pouvez pas le mettre en pause.
Démarrer l'atelier et se connecter à la console Google Cloud
-
Cliquez sur le bouton Démarrer l'atelier. Si l'atelier est payant, un pop-up s'affiche pour vous permettre de sélectionner un mode de paiement. Sur la gauche, vous trouverez le panneau Détails concernant l'atelier, qui contient les éléments suivants :
- Le bouton Ouvrir la console Google
- Le temps restant
- Les identifiants temporaires que vous devez utiliser pour cet atelier
- Des informations complémentaires vous permettant d'effectuer l'atelier
-
Cliquez sur Ouvrir la console Google. L'atelier lance les ressources, puis ouvre la page Se connecter dans un nouvel onglet.
Conseil : Réorganisez les onglets dans des fenêtres distinctes, placées côte à côte.
Remarque : Si la boîte de dialogue Sélectionner un compte s'affiche, cliquez sur Utiliser un autre compte. -
Si nécessaire, copiez le nom d'utilisateur inclus dans le panneau Détails concernant l'atelier et collez-le dans la boîte de dialogue Se connecter. Cliquez sur Suivant.
-
Copiez le mot de passe inclus dans le panneau Détails concernant l'atelier et collez-le dans la boîte de dialogue de bienvenue. Cliquez sur Suivant.
Important : Vous devez utiliser les identifiants fournis dans le panneau de gauche. Ne saisissez pas vos identifiants Google Cloud Skills Boost. Remarque : Si vous utilisez votre propre compte Google Cloud pour cet atelier, des frais supplémentaires peuvent vous être facturés. -
Accédez aux pages suivantes :
- Acceptez les conditions d'utilisation.
- N'ajoutez pas d'options de récupération ni d'authentification à deux facteurs (ce compte est temporaire).
- Ne vous inscrivez pas aux essais offerts.
Après quelques instants, la console Cloud s'ouvre dans cet onglet.

Activer Cloud Shell
Cloud Shell est une machine virtuelle qui contient de nombreux outils pour les développeurs. Elle comprend un répertoire d'accueil persistant de 5 Go et s'exécute sur Google Cloud. Cloud Shell vous permet d'accéder via une ligne de commande à vos ressources Google Cloud.
- Cliquez sur Activer Cloud Shell
en haut de la console Google Cloud.
Une fois connecté, vous êtes en principe authentifié et le projet est défini sur votre ID_PROJET. Le résultat contient une ligne qui déclare YOUR_PROJECT_ID (VOTRE_ID_PROJET) pour cette session :
gcloud est l'outil de ligne de commande pour Google Cloud. Il est préinstallé sur Cloud Shell et permet la complétion par tabulation.
- (Facultatif) Vous pouvez lister les noms des comptes actifs à l'aide de cette commande :
-
Cliquez sur Autoriser.
-
Vous devez à présent obtenir le résultat suivant :
Résultat :
- (Facultatif) Vous pouvez lister les ID de projet à l'aide de cette commande :
Résultat :
Exemple de résultat :
gcloud, dans Google Cloud, accédez au guide de présentation de la gcloud CLI.
Tâche 1 : Vérifier que l'API Dataflow est activée
Pour vous assurer que vous avez bien accès à l'API requise, redémarrez la connexion à l'API Dataflow.
-
Dans la console Cloud, en haut, saisissez "API Dataflow" dans la barre de recherche. Cliquez sur API Dataflow dans les résultats.
-
Cliquez sur Gérer.
-
Cliquez sur Désactiver l'API.
Si vous êtes invité à confirmer votre choix, cliquez sur Désactiver.
- Cliquez sur Activer.
Une fois l'API réactivée, l'option permettant de la désactiver s'affiche sur la page.
Tester la tâche terminée
Cliquez sur Vérifier ma progression pour valider la tâche exécutée.
Tâche 2 : Télécharger le code de démarrage
- Exécutez la commande suivante dans Cloud Shell pour obtenir des exemples Dataflow en Python à partir du dépôt GitHub des services professionnels de Google Cloud :
- Dans Cloud Shell, définissez une variable sur l'ID de votre projet :
Tâche 3 : Créer un bucket Cloud Storage
- Exécutez la commande "make bucket" dans Cloud Shell pour créer un bucket régional dans la région
au sein de votre projet :
Tester la tâche terminée
Cliquez sur Vérifier ma progression pour valider la tâche exécutée.
Tâche 4 : Copier des fichiers dans votre bucket
- Exécutez la commande
gsutildans Cloud Shell pour copier des fichiers dans le bucket Cloud Storage que vous venez de créer :
Tester la tâche terminée
Cliquez sur Vérifier ma progression pour valider la tâche exécutée.
Tâche 5 : Créer l'ensemble de données BigQuery "lake"
- Dans Cloud Shell, créez un ensemble de données BigQuery nommé
lake. C'est par le biais de cet ensemble de données que toutes vos tables seront chargées dans BigQuery :
Tester la tâche terminée
Cliquez sur Vérifier ma progression pour valider la tâche exécutée.
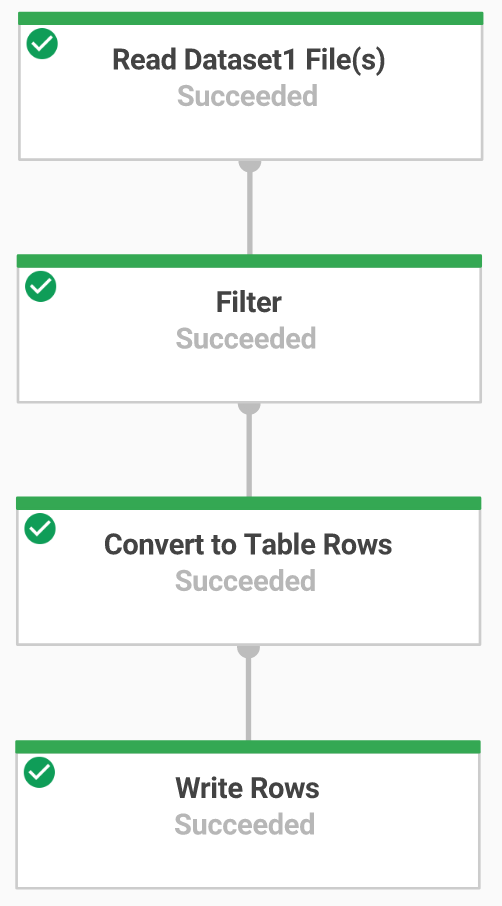
Tâche 6 : Créer un pipeline Dataflow
Dans cette section, vous allez créer un pipeline Dataflow de type "append-only" (ajout uniquement) qui permettra d'ingérer des données dans la table BigQuery. Vous pouvez utiliser l'éditeur de code intégré pour afficher et modifier le code dans la console Google Cloud.
Ouvrir l'éditeur de code Cloud Shell
- Pour accéder au code source, cliquez sur l'icône Ouvrir l'éditeur dans Cloud Shell :

- Si vous y êtes invité, cliquez sur Ouvrir dans une nouvelle fenêtre. L'éditeur de code s'ouvrira en ce cas dans une nouvelle fenêtre. L'éditeur Cloud Shell vous permet de modifier des fichiers dans l'environnement Cloud Shell. Lorsque vous vous trouvez dans l'éditeur, vous pouvez revenir à Cloud Shell en cliquant sur Ouvrir le terminal.
Tâche 7 : Ingestion de données avec un pipeline Dataflow
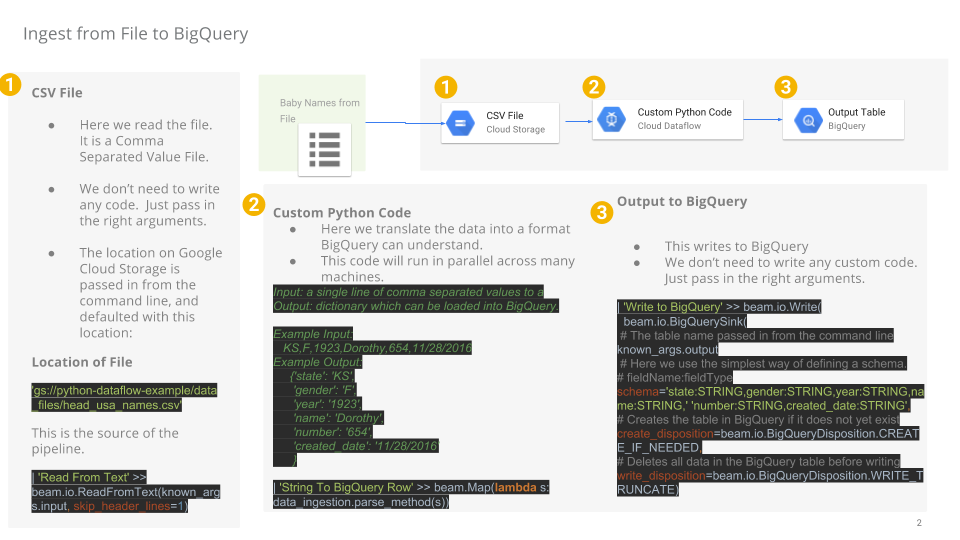
Vous allez maintenant créer un pipeline Dataflow avec une source TextIO et une destination BigQueryIO pour ingérer des données dans BigQuery. Les opérations à réaliser sont les suivantes :
- Ingérer les fichiers à partir de Cloud Storage
- Filtrer la ligne d'en-tête dans les fichiers
- Convertir les lignes lues en objets de dictionnaire
- Envoyer les lignes dans BigQuery
Tâche 8 : Examiner le code Python du pipeline
Dans l'éditeur de code, accédez à dataflow-python-examples > dataflow_python_examples, puis ouvrez le fichier data_ingestion.py. Lisez les commentaires expliquant les actions effectuées par le code. Ce code ajoute une table à l'ensemble de données lake dans BigQuery.
Tâche 9 : Exécuter le pipeline Apache Beam
- Pour effectuer cette étape, revenez dans votre session Cloud Shell. Vous allez procéder à quelques opérations de configuration pour les bibliothèques Python requises.
Le job Dataflow de cet atelier nécessite Python 3.8. Pour vous assurer d'utiliser la bonne version, vous allez exécuter les processus Dataflow dans un conteneur Docker Python 3.8.
- Exécutez la commande suivante dans Cloud Shell pour démarrer un conteneur Python :
Cette commande extrait un conteneur Docker avec la dernière version stable de Python 3.8, puis lance un shell de commande vous permettant d'exécuter les prochaines commandes dans votre conteneur. L'option -v fournit le code source en tant que volume pour le conteneur. Ainsi, nous pouvons le modifier dans l'éditeur Cloud Shell tout en gardant la possibilité d'y accéder dans le conteneur en cours d'exécution.
- Dès que l'extraction du conteneur est terminée et que celui-ci est lancé dans Cloud Shell, exécutez la commande suivante pour installer
apache-beamdans ce conteneur en cours d'exécution :
- Ensuite, dans le conteneur en cours d'exécution dans Cloud Shell, accédez au répertoire auquel vous avez associé le code source :
Exécuter le pipeline d'ingestion Dataflow dans le cloud
- Le code suivant lancera les nœuds de calcul requis et les fermera à la fin du processus :
- Revenez à la console Cloud et accédez au menu de navigation > Dataflow pour afficher l'état de votre job.

-
Cliquez sur le nom de votre job pour voir sa progression. Lorsque l'état du job indique Réussite, vous pouvez passer à l'étape suivante. Le démarrage, l'exécution et l'arrêt de ce pipeline Dataflow prennent au total environ cinq minutes.
-
Accédez à BigQuery (Menu de navigation > BigQuery) pour vérifier que vos données ont bien été intégrées.
- Cliquez sur le nom du projet pour afficher la table usa_names sous l'ensemble de données
lake.

- Cliquez sur la table, puis accédez à l'onglet Aperçu pour afficher des exemples de données de
usa_names.
usa_names n'apparaît pas, actualisez la page ou essayez d'afficher les tables dans l'UI classique de BigQuery.
Tester la tâche terminée
Cliquez sur Vérifier ma progression pour valider la tâche exécutée.
Tâche 10 : Transformation des données
Vous allez maintenant créer un pipeline Dataflow avec une source TextIO et une destination BigQueryIO pour ingérer des données dans BigQuery. Les opérations à réaliser sont les suivantes :
- Ingérer les fichiers à partir de Cloud Storage
- Convertir les lignes lues en objets de dictionnaire
- Transformer les données qui contiennent l'année dans un format que BigQuery reconnaît comme une date
- Envoyer les lignes dans BigQuery
Examiner le code Python du pipeline de transformation
Dans l'éditeur de code, ouvrez le fichier data_transformation.py. Lisez les commentaires expliquant les actions effectuées par le code.
Tâche 11 : Exécuter le pipeline de transformation Dataflow
Vous allez exécuter le pipeline Dataflow dans le cloud. Ce code lancera les nœuds de calcul requis et les fermera à la fin du processus.
- Pour ce faire, exécutez les commandes suivantes :
-
Accédez au menu de navigation > Dataflow, puis cliquez sur le nom du job pour afficher son état. Le démarrage, l'exécution et l'arrêt de ce pipeline Dataflow prennent au total environ cinq minutes.
-
Lorsque l'état du job indique Réussite dans l'écran Dataflow, accédez à BigQuery pour vérifier que vos données ont bien été intégrées.
-
Vous devez voir la table usa_names_transformed sous l'ensemble de données
lake. -
Cliquez sur la table, puis accédez à l'onglet Aperçu pour afficher des exemples de données de
usa_names_transformed.
usa_names_transformed n'apparaît pas, actualisez la page ou essayez d'afficher les tables dans l'UI classique de BigQuery.
Tester la tâche terminée
Cliquez sur Vérifier ma progression pour valider la tâche exécutée.
Tâche 12 : Enrichissement des données
Vous allez maintenant créer un pipeline Dataflow avec une source TextIO et une destination BigQueryIO pour ingérer des données dans BigQuery. Les opérations à réaliser sont les suivantes :
- Ingérer les fichiers à partir de Cloud Storage
- Filtrer la ligne d'en-tête dans les fichiers
- Convertir les lignes lues en objets de dictionnaire
- Envoyer les lignes dans BigQuery
Tâche 13 : Examiner le code Python du pipeline d'enrichissement de données
-
Dans l'éditeur de code, ouvrez le fichier
data_enrichment.py. -
Lisez les commentaires expliquant les actions effectuées par le code. Ce code envoie les données vers BigQuery.
La ligne 83 se présente actuellement comme suit :
- Modifiez-la de sorte qu'elle ressemble à ceci :
- Lorsque vous avez terminé de modifier cette ligne, n'oubliez pas d'enregistrer le fichier mis à jour. Pour ce faire, cliquez sur le menu déroulant Fichier de l'éditeur, puis sur Enregistrer.
Tâche 14 : Exécuter le pipeline Dataflow d'enrichissement de données
Vous allez maintenant exécuter le pipeline Dataflow dans le cloud.
- Exécutez le code suivant dans Cloud Shell pour lancer les nœuds de calcul requis et les arrêter à la fin du processus :
-
Accédez au menu de navigation > Dataflow pour afficher l'état de votre job. Le démarrage, l'exécution et l'arrêt de ce pipeline Dataflow prennent au total environ cinq minutes.
-
Lorsque l'état du job indique Réussite dans l'écran Dataflow, accédez à BigQuery pour vérifier que vos données ont bien été intégrées.
Vous devez voir la table usa_names_enriched sous l'ensemble de données lake.
- Cliquez sur la table, puis accédez à l'onglet Aperçu pour afficher des exemples de données de
usa_names_enriched.
usa_names_enriched n'apparaît pas, actualisez la page ou essayez d'afficher les tables dans l'UI classique de BigQuery.
Tester la tâche d'enrichissement de données terminée
Cliquez sur Vérifier ma progression pour valider la tâche exécutée.
Tâche 15 : Créer un pipeline entre le lac de données et un magasin et examiner le code Python du pipeline
Créez maintenant un pipeline Dataflow qui lit les données de deux sources de données BigQuery et les associe. Les opérations à réaliser sont les suivantes :
- Ingérer les fichiers de deux sources BigQuery
- Associer les deux sources de données
- Filtrer la ligne d'en-tête dans les fichiers
- Convertir les lignes lues en objets de dictionnaire
- Envoyer les lignes dans BigQuery
Dans l'éditeur de code, ouvrez le fichier data_lake_to_mart.py. Lisez les commentaires expliquant les actions effectuées par le code. Ce code associe deux tables et insère les données obtenues dans BigQuery.
Tâche 16 : Exécuter le pipeline Apache Beam pour associer les données et créer la table qui en résulte dans BigQuery
Exécutez maintenant le pipeline Dataflow dans le cloud.
- Exécutez le bloc de code suivant dans Cloud Shell pour lancer les nœuds de calcul requis et les arrêter à la fin du processus :
-
Accédez au menu de navigation > Dataflow, puis cliquez sur le nom de ce nouveau job pour afficher son état. Le démarrage, l'exécution et l'arrêt de ce pipeline Dataflow prennent au total environ cinq minutes.
-
Lorsque l'état du job indique Réussite dans l'écran Dataflow, accédez à BigQuery pour vérifier que vos données ont bien été intégrées.
Vous devez voir la table orders_denormalized_sideinput sous l'ensemble de données lake.
- Cliquez sur la table, puis accédez à l'onglet Aperçu pour afficher des exemples de données de
orders_denormalized_sideinput.
orders_denormalized_sideinput n'apparaît pas, actualisez la page ou essayez d'afficher les tables dans l'UI classique de BigQuery.
Tester la tâche JOIN terminée
Cliquez sur Vérifier ma progression pour valider la tâche exécutée.
Tester vos connaissances
Voici quelques questions à choix multiples qui vous permettront de mieux maîtriser les concepts abordés lors de cet atelier. Répondez-y du mieux que vous le pouvez.
Félicitations !
Vous avez utilisé des fichiers Python pour ingérer des données dans BigQuery à l'aide de Dataflow.
Terminer votre quête
Cet atelier d'auto-formation fait partie de la quête Data Engineering. Une quête est une série d'ateliers associés qui constituent un parcours de formation. Si vous terminez cette quête, vous obtenez un badge attestant de votre réussite. Vous pouvez rendre publics les badges que vous recevez et ajouter leur lien dans votre CV en ligne ou sur vos comptes de réseaux sociaux. Inscrivez-vous à cette quête pour obtenir immédiatement les crédits associés à cet atelier si vous l'avez suivi. Découvrez les autres quêtes disponibles.
Atelier suivant
Continuez votre quête avec l'atelier Prédire les achats des visiteurs avec un modèle de classification dans BQML ou consultez nos suggestions :
Étapes suivantes et informations supplémentaires
Vous souhaitez en savoir plus ? Consultez la documentation officielle sur :
- Google Dataflow
- BigQuery
- Consultez également le guide de programmation d'Apache Beam pour accéder à des informations sur les concepts avancés.
Formations et certifications Google Cloud
Les formations et certifications Google Cloud vous aident à tirer pleinement parti des technologies Google Cloud. Nos cours portent sur les compétences techniques et les bonnes pratiques à suivre pour être rapidement opérationnel et poursuivre votre apprentissage. Nous proposons des formations pour tous les niveaux, à la demande, en salle et à distance, pour nous adapter aux emplois du temps de chacun. Les certifications vous permettent de valider et de démontrer vos compétences et votre expérience en matière de technologies Google Cloud.
Dernière modification du manuel : 12 octobre 2023
Dernier test de l'atelier : 12 octobre 2023
Copyright 2024 Google LLC Tous droits réservés. Google et le logo Google sont des marques de Google LLC. Tous les autres noms d'entreprises et de produits peuvent être des marques des entreprises auxquelles ils sont associés.