Checkpoints
Disable and re-enable the Dataflow API
/ 10
Create a Cloud Storage Bucket
/ 10
Copy Files to Your Bucket
/ 10
Create the BigQuery Dataset (name: lake)
/ 20
Build a Data Ingestion Dataflow Pipeline
/ 10
Build a Data Transformation Dataflow Pipeline
/ 10
Build a Data Enrichment Dataflow Pipeline
/ 10
Build a Data lake to Mart Dataflow Pipeline
/ 20
Processamento ETL no Google Cloud com o Dataflow e o BigQuery (Python)
- GSP290
- Informações gerais
- Configuração
- Tarefa 1: verifique se a API Dataflow está ativada
- Tarefa 2: faça o download do código inicial
- Tarefa 3: crie o bucket do Cloud Storage
- Tarefa 4: copie os arquivos para o bucket
- Tarefa 5: crie o conjunto de dados "lake" do BigQuery
- Tarefa 6: crie um pipeline do Dataflow
- Tarefa 7: realize a ingestão de dados com um pipeline do Dataflow
- Tarefa 8: revise o código Python do pipeline
- Tarefa 9: execute o pipeline do Apache Beam
- Tarefa 10: transformação de dados
- Tarefa 11. execute o pipeline de transformação do Dataflow
- Tarefa 12. realize o aprimoramento de dados
- Tarefa 13. revise o código Python do pipeline de enriquecimento de dados
- Tarefa 14. execute o pipeline de enriquecimento de dados do Dataflow
- Tarefa 15: código Python do pipeline "Conversão de data lake em data mart e revisão"
- Tarefa 16: execute o pipeline do Apache Beam para realizar a mesclagem de dados e criar a tabela resultante no BigQuery
- Teste seu conhecimento
- Parabéns!
GSP290

Informações gerais
Neste laboratório, você vai criar vários pipelines de dados que ingerem dados de um conjunto disponível publicamente no BigQuery usando estes serviços do Google Cloud:
- Cloud Storage
- Dataflow
- BigQuery
Você criará seu próprio pipeline de dados, incluindo as considerações sobre o design e os detalhes da implementação, para garantir que o protótipo atenda aos requisitos. Quando solicitado, abra os arquivos Python e leia os comentários.
Configuração
Antes de clicar no botão Start Lab
Leia estas instruções. Os laboratórios são cronometrados e não podem ser pausados. O timer é iniciado quando você clica em Começar o laboratório e mostra por quanto tempo os recursos do Google Cloud vão ficar disponíveis.
Este laboratório prático permite que você realize as atividades em um ambiente real de nuvem, não em uma simulação ou demonstração. Você vai receber novas credenciais temporárias para fazer login e acessar o Google Cloud durante o laboratório.
Confira os requisitos para concluir o laboratório:
- Acesso a um navegador de Internet padrão (recomendamos o Chrome).
- Tempo para concluir o laboratório---não se esqueça: depois de começar, não será possível pausar o laboratório.
Como iniciar seu laboratório e fazer login no console do Google Cloud
-
Clique no botão Começar o laboratório. Se for preciso pagar, você verá um pop-up para selecionar a forma de pagamento. No painel Detalhes do laboratório à esquerda, você verá o seguinte:
- O botão Abrir Console do Cloud
- Tempo restante
- As credenciais temporárias que você vai usar neste laboratório
- Outras informações se forem necessárias
-
Clique em Abrir Console do Google. O laboratório ativa recursos e depois abre outra guia com a página Fazer login.
Dica: coloque as guias em janelas separadas lado a lado.
Observação: se aparecer a caixa de diálogo Escolher uma conta, clique em Usar outra conta. -
Caso seja preciso, copie o Nome de usuário no painel Detalhes do laboratório e cole esse nome na caixa de diálogo Fazer login. Clique em Avançar.
-
Copie a Senha no painel Detalhes do laboratório e a cole na caixa de diálogo Olá. Clique em Avançar.
Importante: você precisa usar as credenciais do painel à esquerda. Não use suas credenciais do Google Cloud Ensina. Observação: se você usar sua própria conta do Google Cloud neste laboratório, é possível que receba cobranças adicionais. -
Acesse as próximas páginas:
- Aceite os Termos e Condições.
- Não adicione opções de recuperação nem autenticação de dois fatores (porque essa é uma conta temporária).
- Não se inscreva em testes gratuitos.
Depois de alguns instantes, o console do GCP vai ser aberto nesta guia.

Ativar o Cloud Shell
O Cloud Shell é uma máquina virtual com várias ferramentas de desenvolvimento. Ele tem um diretório principal permanente de 5 GB e é executado no Google Cloud. O Cloud Shell oferece acesso de linha de comando aos recursos do Google Cloud.
- Clique em Ativar o Cloud Shell
na parte de cima do console do Google Cloud.
Depois de se conectar, vai notar que sua conta já está autenticada, e que o projeto está configurado com seu PROJECT_ID. A saída contém uma linha que declara o projeto PROJECT_ID para esta sessão:
gcloud é a ferramenta de linha de comando do Google Cloud. Ela vem pré-instalada no Cloud Shell e aceita preenchimento com tabulação.
- (Opcional) É possível listar o nome da conta ativa usando este comando:
-
Clique em Autorizar.
-
A saída será parecida com esta:
Saída:
- (Opcional) É possível listar o ID do projeto usando este comando:
Saída:
Exemplo de saída:
gcloud, acesse o guia com informações gerais sobre a gcloud CLI no Google Cloud.
Tarefa 1: verifique se a API Dataflow está ativada
Para ter acesso à API Dataflow, reinicie a conexão.
-
No console do Cloud, digite "API Dataflow" na barra de pesquisa superior. Clique no resultado para API Dataflow.
-
Selecione Gerenciar.
-
Clique em Desativar API.
Se for necessário confirmar, clique em Desativar.
- Selecione Ativar.
A opção para desativar a API aparece quando ela é ativada novamente.
Teste a tarefa concluída
Clique em Verificar meu progresso para conferir a tarefa realizada.
Tarefa 2: faça o download do código inicial
- Execute o seguinte comando no Cloud Shell para acessar exemplos de Python do Dataflow no GitHub dos serviços profissionais do Google Cloud:
- Agora, defina uma variável igual ao ID do projeto no Cloud Shell.
Tarefa 3: crie o bucket do Cloud Storage
- Use o comando "make bucket" no Cloud Shell para criar um bucket regional na região
do projeto:
Teste a tarefa concluída
Clique em Verificar meu progresso para conferir a tarefa realizada.
Tarefa 4: copie os arquivos para o bucket
- Use o comando
gsutilno Cloud Shell a fim de copiar arquivos para o bucket do Cloud Storage que você acabou de criar:
Teste a tarefa concluída
Clique em Verificar meu progresso para conferir a tarefa realizada.
Tarefa 5: crie o conjunto de dados "lake" do BigQuery
- No Cloud Shell, crie um conjunto de dados no BigQuery chamado
lake. É nesse local que todas as suas tabelas serão carregadas no BigQuery:
Teste a tarefa concluída
Clique em Verificar meu progresso para conferir a tarefa realizada.
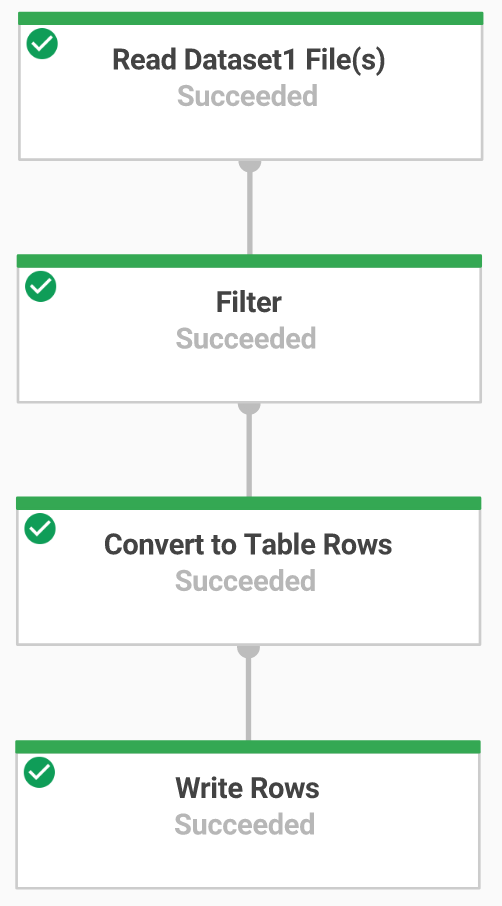
Tarefa 6: crie um pipeline do Dataflow
Nesta seção, você criará um Dataflow somente de anexação que fará a ingestão de dados na tabela do BigQuery. Use o editor de código integrado para exibir e editar o código no console do Google Cloud.
Abrir o editor de código do Cloud Shell
- Acesse o código-fonte clicando no ícone Abrir editor no Cloud Shell:

- Se for solicitado, clique em Abrir em uma nova janela. Isso vai abrir o editor de código em uma nova janela. Com o editor do Cloud Shell, você pode editar arquivos no ambiente do Cloud Shell. Quando estiver no Editor, basta clicar em Abrir terminal para retornar ao Cloud Shell.
Tarefa 7: realize a ingestão de dados com um pipeline do Dataflow
Agora você criará um pipeline do Dataflow com origem TextIO e destino BigQueryIO para fazer a ingestão de dados no BigQuery. Mais especificamente, ele deverá:
- ingerir os arquivos do Cloud Storage;
- filtrar a linha de cabeçalho nos arquivos;
- converter as linhas lidas em objetos de dicionário;
- enviar as linhas para o BigQuery.
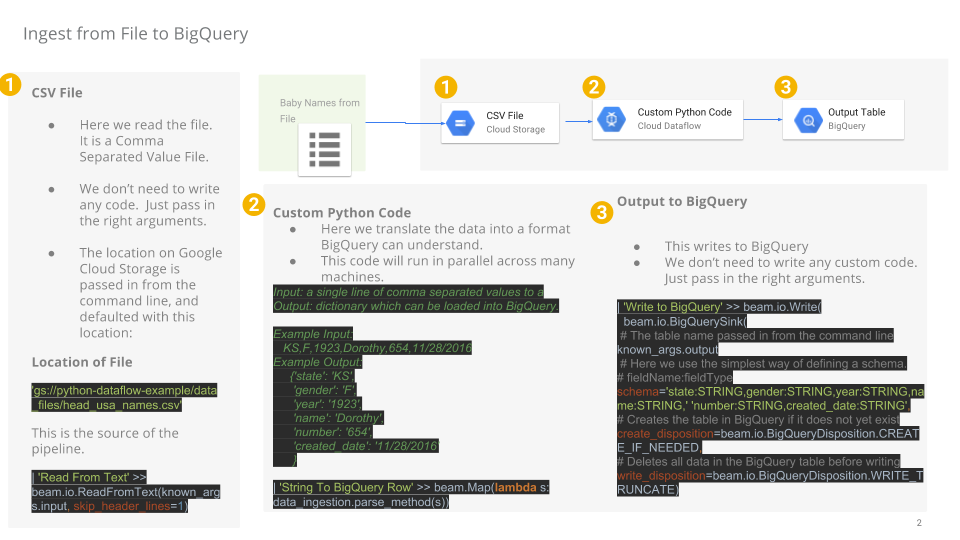
Tarefa 8: revise o código Python do pipeline
No Editor de código, acesse dataflow-python-examples > dataflow_python_examples e abra o arquivo data_ingestion.py. Leia os comentários que explicam o que o código faz. Ele vai preencher o conjunto de dados lake com uma tabela no BigQuery.
Tarefa 9: execute o pipeline do Apache Beam
- Volte à sessão do Cloud Shell para realizar esta etapa. Agora você precisa configurar as bibliotecas Python necessárias.
O job do Dataflow neste laboratório exige o Python 3.8. Para verificar se você tem a versão adequada, execute os processos do Dataflow em um contêiner do Docker com Python 3.8.
- Execute o seguinte comando no Cloud Shell para iniciar um contêiner com Python:
Este comando vai extrair um contêiner do Docker com a versão estável mais recente do Python 3.8 e executar um shell de comando para a execução dos próximos comandos no contêiner. A flag -v fornece o código-fonte como um volume para o contêiner, para permitir a edição do código no editor do Cloud Shell e manter o acesso a ele no contêiner em execução.
- Depois que o contêiner terminar a extração e começar a ser executado no Cloud Shell, execute o seguinte comando para instalar o
apache-beamnele:
- Em seguida, no contêiner que está em execução no Cloud Shell, altere os diretórios para o local em que você vinculou o código-fonte:
Execute o pipeline de ingestão do Dataflow na nuvem.
- O seguinte código ativará os workers necessários e os desativará quando estiverem concluídos:
- Volte ao console do Cloud e abra Menu de navegação > Dataflow para conferir o status do job.

-
Clique no nome do job para conferir o progresso dele. Quando o Status do job aparecer como Concluído, siga para a próxima etapa. Esse pipeline do Dataflow vai levar cerca de cinco minutos para ser iniciado, concluir o trabalho e ser encerrado.
-
Acesse o BigQuery (Menu de navegação > BigQuery) e confira se os dados foram preenchidos.
- Clique no nome do projeto para exibir a tabela usa_names no conjunto de dados
lake.

- Clique na tabela e acesse a guia Visualização para exibir exemplos dos dados de
usa_names.
usa_names não for exibida, tente atualizar a página ou visualizar as tabelas usando a interface clássica do BigQuery.
Teste a tarefa concluída
Clique em Verificar meu progresso para conferir a tarefa realizada.
Tarefa 10: transformação de dados
Agora você criará um pipeline do Dataflow com origem TextIO e destino BigQueryIO para fazer a ingestão de dados no BigQuery. Mais especificamente, você vai fazer o seguinte:
- ingerir os arquivos do Cloud Storage;
- converter as linhas lidas em objetos de dicionário;
- transformar os dados que contêm o ano em um formato que o BigQuery possa entender como data;
- enviar as linhas para o BigQuery.
Revise o código Python do pipeline de transformação
No editor de código, abra o arquivo data_transformation.py. Leia os comentários que explicam o que o código faz.
Tarefa 11. execute o pipeline de transformação do Dataflow
Você executará o pipeline do Dataflow na nuvem. Isso ativará os workers necessários e os desativará quando estiverem concluídos.
- Para fazer isso, execute os comandos a seguir:
-
Acesse Menu de navegação > Dataflow e clique no nome do job para exibir o status dele. Esse pipeline do Dataflow vai levar cerca de cinco minutos para ser iniciado, concluir o trabalho e ser encerrado.
-
Quando o Status do job aparecer como Concluído na tela correspondente do Dataflow, acesse o BigQuery para verificar se os dados foram preenchidos.
-
A tabela usa_names_transformed deve aparecer abaixo do conjunto de dados
lake. -
Clique na tabela e acesse a guia Visualização para consultar exemplos dos dados de
usa_names_transformed.
usa_names_transformed não for exibida, atualize a página ou visualize as tabelas usando a interface clássica do BigQuery.
Teste a tarefa concluída
Clique em Verificar meu progresso para conferir a tarefa realizada.
Tarefa 12. realize o aprimoramento de dados
Agora você criará um pipeline do Dataflow com origem TextIO e destino BigQueryIO para fazer a ingestão de dados no BigQuery. Mais especificamente, você vai fazer o seguinte:
- ingerir os arquivos do Cloud Storage;
- filtrar a linha de cabeçalho nos arquivos;
- converter as linhas lidas em objetos de dicionário;
- enviar as linhas para o BigQuery.
Tarefa 13. revise o código Python do pipeline de enriquecimento de dados
-
No editor de código, abra o arquivo
data_enrichment.py. -
Confira os comentários que explicam o que o código faz. Esse código preencherá os dados no BigQuery.
No momento, esta é a linha 83:
- Faça as seguintes alterações nessa linha:
- Depois de editar a linha, lembre-se de salvar este arquivo atualizado selecionando o menu suspenso Arquivo no Editor e clicando em Salvar.
Tarefa 14. execute o pipeline de enriquecimento de dados do Dataflow
Agora você executará o pipeline do Dataflow na nuvem.
- Execute o seguinte comando no Cloud Shell para ativar os workers necessários e encerrá-los após a conclusão:
-
Acesse Menu de navegação > Dataflow para conferir o status do job. Esse pipeline do Dataflow vai levar cerca de cinco minutos para ser iniciado, concluir o trabalho e ser encerrado.
-
Quando o Status do job aparecer como Concluído na tela correspondente do Dataflow, acesse o BigQuery para verificar se os dados foram preenchidos.
A tabela usa_names_enriched será exibida abaixo do conjunto de dados lake.
- Clique na tabela e acesse a guia Visualização para exibir exemplos dos dados de
usa_names_enriched.
usa_names_enriched não for exibida, atualize a página ou visualize as tabelas usando a interface clássica do BigQuery.
Teste a tarefa de enriquecimento de dados concluída
Clique em Verificar meu progresso para conferir a tarefa realizada.
Tarefa 15: código Python do pipeline "Conversão de data lake em data mart e revisão"
Agora crie um pipeline do Dataflow que leia dados de duas fontes de dados do BigQuery e mescle essas fontes. Mais especificamente, você vai fazer o seguinte:
- ingerir arquivos de duas fontes do BigQuery;
- mesclar as duas fontes de dados;
- filtrar a linha de cabeçalho nos arquivos;
- converter as linhas lidas em objetos de dicionário;
- enviar as linhas para o BigQuery.
No Editor de código, abra o arquivo data_lake_to_mart.py. Leia os comentários que explicam o que o código faz. Esse código vai mesclar duas tabelas e preencher os dados resultantes no BigQuery.
Tarefa 16: execute o pipeline do Apache Beam para realizar a mesclagem de dados e criar a tabela resultante no BigQuery
Agora, execute o pipeline do Dataflow na nuvem.
- Execute o seguinte bloco de código no Cloud Shell para ativar os workers necessários e encerrá-los após a conclusão:
-
Acesse o Menu de navegação > Dataflow e clique no nome do novo job para conferir o status dele. Esse pipeline do Dataflow vai levar cerca de cinco minutos para ser iniciado, concluir o trabalho e ser encerrado.
-
Quando o Status do job aparecer como Concluído na tela correspondente do Dataflow, acesse o BigQuery para verificar se os dados foram preenchidos.
A tabela orders_denormalized_sideinput será exibida abaixo do conjunto de dados lake.
- Clique na tabela e acesse a seção Visualização para exibir exemplos dos dados de
orders_denormalized_sideinput.
orders_denormalized_sideinput não for exibida, atualize a página ou visualize as tabelas usando a interface clássica do BigQuery.
Teste a tarefa JOIN concluída
Clique em Verificar meu progresso para conferir a tarefa realizada.
Teste seu conhecimento
Responda às perguntas de múltipla escolha abaixo para reforçar sua compreensão dos conceitos abordados neste laboratório. Use tudo o que você aprendeu até aqui.
Parabéns!
Você utilizou arquivos Python para ingerir dados no BigQuery usando o Dataflow.
Termine a Quest
Este laboratório autoguiado faz parte da Quest Data Engineering. Uma Quest é uma série de laboratórios relacionados que formam um programa de aprendizado. Ao concluir esta Quest, você recebe o selo como reconhecimento pela sua conquista. É possível publicar os selos que você ganhou e incluir um link para eles no seu currículo on-line ou nas redes sociais. Caso você já tenha realizado este laboratório, inscreva-se nesta Quest para ganhar os créditos de conclusão imediatamente. Confira outras Quests disponíveis.
Comece o próximo laboratório
Continue sua Quest com o laboratório Preveja compras de visitantes com um modelo de classificação no BQML ou confira estas sugestões:
Próximas etapas / Saiba mais
Quer saber mais? Confira a documentação oficial:
- Google Dataflow
- BigQuery
- Guia de programação do Apache Beam (em inglês) para conceitos mais avançados
Treinamento e certificação do Google Cloud
Esses treinamentos ajudam você a aproveitar as tecnologias do Google Cloud ao máximo. Nossas aulas incluem habilidades técnicas e práticas recomendadas para ajudar você a alcançar rapidamente o nível esperado e continuar sua jornada de aprendizado. Oferecemos treinamentos que vão do nível básico ao avançado, com opções de aulas virtuais, sob demanda e por meio de transmissões ao vivo para que você possa encaixá-las na correria do seu dia a dia. As certificações validam sua experiência e comprovam suas habilidades com as tecnologias do Google Cloud.
Manual atualizado em 12 de outubro de 2023
Laboratório testado em 12 de outubro de 2023
Copyright 2024 Google LLC. Todos os direitos reservados. Google e o logotipo do Google são marcas registradas da Google LLC. Todos os outros nomes de produtos e empresas podem ser marcas registradas das respectivas empresas a que estão associados.