チェックポイント
Query a public dataset (dataset: usa_names, table: usa_1910_2013)
/ 30
Create a new dataset
/ 40
Query new dataset
/ 30
Google Cloud コンソールで BigQuery を使用する
GSP406

概要
適切なハードウェアとインフラストラクチャを用意することなく大規模なデータセットを保存してクエリを実行すると、多大な時間と費用がかかってしまう可能性があります。エンタープライズ データ ウェアハウスである Google BigQuery は、Google のインフラストラクチャの処理能力を活用して SQL クエリを超高速で実行し、こうした問題を解決します。ユーザーはデータを BigQuery に読み込むだけです。残りの処理は Google 側で行います。他のユーザーにデータの表示やクエリを許可するなど、ビジネスニーズに基づいてプロジェクトとデータへのアクセスを制御できます。
BigQuery にアクセスするには、Cloud Console またはコマンドライン ツールを使用するか、Java、.NET、Python などの各種クライアント ライブラリを使って BigQuery REST API を呼び出します。データを可視化したり、データを読み込んだりするなど、BigQuery の操作に使用できるサードパーティ製ツールは多種多様です。このラボでは、Cloud コンソールを使って BigQuery にアクセスします。
Cloud コンソールから BigQuery を利用することで、クエリの実行、データの読み込みやエクスポートといったタスクを視覚的なインターフェースから行うことができます。このハンズオンラボでは、Google Cloud コンソールを使用して、一般公開データセット内のテーブルに対してクエリを実行する方法と、BigQuery にサンプルデータを読み込む方法について学習します。
演習内容
このラボでは、次の作業を行います。
- 一般公開データセットに対してクエリを実行する
- カスタム テーブルを作成する
- テーブルにデータを読み込む
- テーブルに対してクエリを実行する
設定と要件
Qwiklabs の設定
[ラボを開始] ボタンをクリックする前に
こちらの手順をお読みください。ラボの時間は記録されており、一時停止することはできません。[ラボを開始] をクリックするとスタートするタイマーは、Google Cloud のリソースを利用できる時間を示しています。
このハンズオンラボでは、シミュレーションやデモ環境ではなく、実際のクラウド環境を使ってご自身でラボのアクティビティを行うことができます。そのため、ラボの受講中に Google Cloud にログインおよびアクセスするための、新しい一時的な認証情報が提供されます。
このラボを完了するためには、下記が必要です。
- 標準的なインターネット ブラウザ(Chrome を推奨)
- ラボを完了するために十分な時間を確保してください。ラボをいったん開始すると一時停止することはできません。
Google Cloud コンソール
ラボを開始して Google Cloud コンソールにログインする方法
-
[ラボを開始] ボタンをクリックします。ラボの料金をお支払いいただく必要がある場合は、表示されるポップアップでお支払い方法を選択してください。 左側の [ラボの詳細] パネルには、以下が表示されます。
- [Google コンソールを開く] ボタン
- 残り時間
- このラボで使用する必要がある一時的な認証情報
- このラボを行うために必要なその他の情報(ある場合)
-
[Google コンソールを開く] をクリックします。 ラボでリソースが起動し、別のタブで [ログイン] ページが表示されます。
ヒント: タブをそれぞれ別のウィンドウで開き、並べて表示しておきましょう。
注: [アカウントの選択] ダイアログが表示されたら、[別のアカウントを使用] をクリックします。 -
必要に応じて、[ラボの詳細] パネルから [ユーザー名] をコピーして [ログイン] ダイアログに貼り付けます。[次へ] をクリックします。
-
[ラボの詳細] パネルから [パスワード] をコピーして [ようこそ] ダイアログに貼り付けます。[次へ] をクリックします。
重要: 認証情報は左側のパネルに表示されたものを使用してください。Google Cloud Skills Boost の認証情報は使用しないでください。 注: このラボでご自身の Google Cloud アカウントを使用すると、追加料金が発生する場合があります。 -
その後次のように進みます。
- 利用規約に同意してください。
- 一時的なアカウントなので、復元オプションや 2 要素認証プロセスは設定しないでください。
- 無料トライアルには登録しないでください。
その後このタブで Cloud Console が開きます。

タスク 1. BigQuery を開く
BigQuery コンソールには、テーブルに対してクエリを実行するためのインターフェースが用意されており、BigQuery が提供する一般公開データセットも利用できます。
BigQuery コンソールを開く
- Google Cloud コンソールで、ナビゲーション メニュー > [BigQuery] を選択します。
[Cloud コンソールの BigQuery へようこそ] メッセージ ボックスが開きます。このメッセージ ボックスには、クイックスタート ガイドとリリースノートへのリンクが表示されます。
- [完了] をクリックします。
BigQuery コンソールが開きます。
タスク 2. 一般公開データセットに対してクエリを実行する
このセクションでは、一般公開データセットの USA Names を BigQuery に読み込んでクエリを実行し、1910 年から 2013 年の間に米国で最も多かった名前を特定します。
USA Names データセットを読み込む
-
[エクスプローラ] ペインで、[+ 追加] をクリックします。
-
[追加] ウィンドウで、[名前を指定してプロジェクトにスターを付ける] を選択します。
-
プロジェクト名の入力フィールドに「
bigquery-public-data」と入力し、[スターを付ける] をクリックします。
プロジェクト bigquery-public-data がリソースに追加され、左側のペインの [エクスプローラ] セクションにある bigquery-public-data の下にデータセット usa_names が表示されます。
-
[usa_names] をクリックしてデータセットを展開します。
-
[usa_1910_2013] をクリックして、このテーブルを開きます。
USA Names データセットに対してクエリを実行する
bigquery-public-data.usa_names.usa_1910_2013 に対してクエリを実行します。このデータセットで新生児の名前と性別を調べて、上位 10 件の名前を降順で表示します。
-
[クエリ] > [新しいタブ] をクリックします。
-
クエリエディタ内のデフォルトのクエリテキストを削除します。
-
次のクエリをコピーして、クエリエディタのテキスト領域に貼り付けます。
- ウィンドウの右上のクエリ バリデータを確認します。
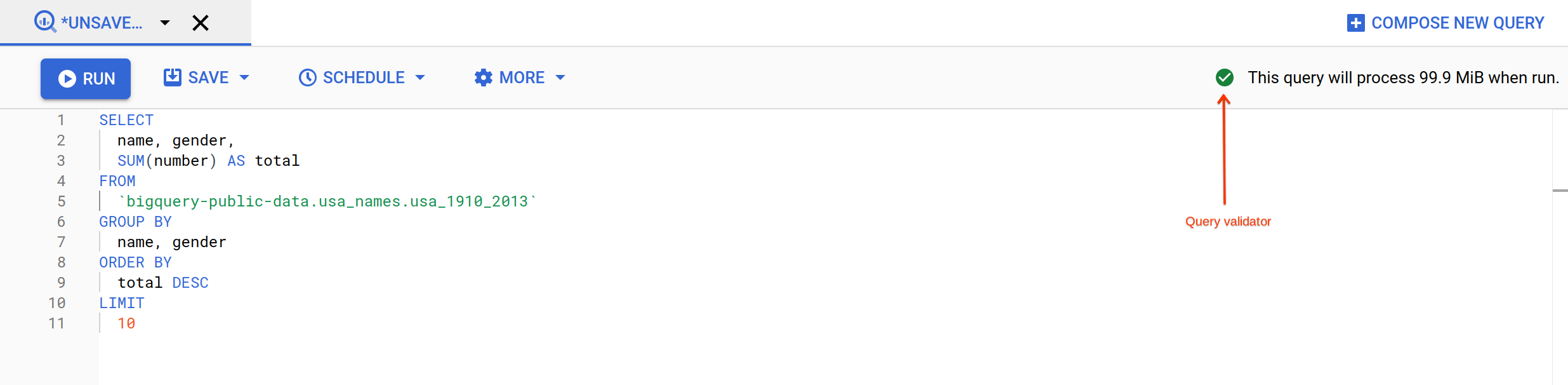
クエリが有効な場合は、緑色のチェックマーク アイコンが表示されます。クエリが無効な場合は、赤色の感嘆符アイコンが表示されます。クエリが有効な場合は、クエリの実行時に処理されるデータ量も確認できます。これは、クエリ実行のコストを判断するのに役立ちます。
- [実行] をクリックします。
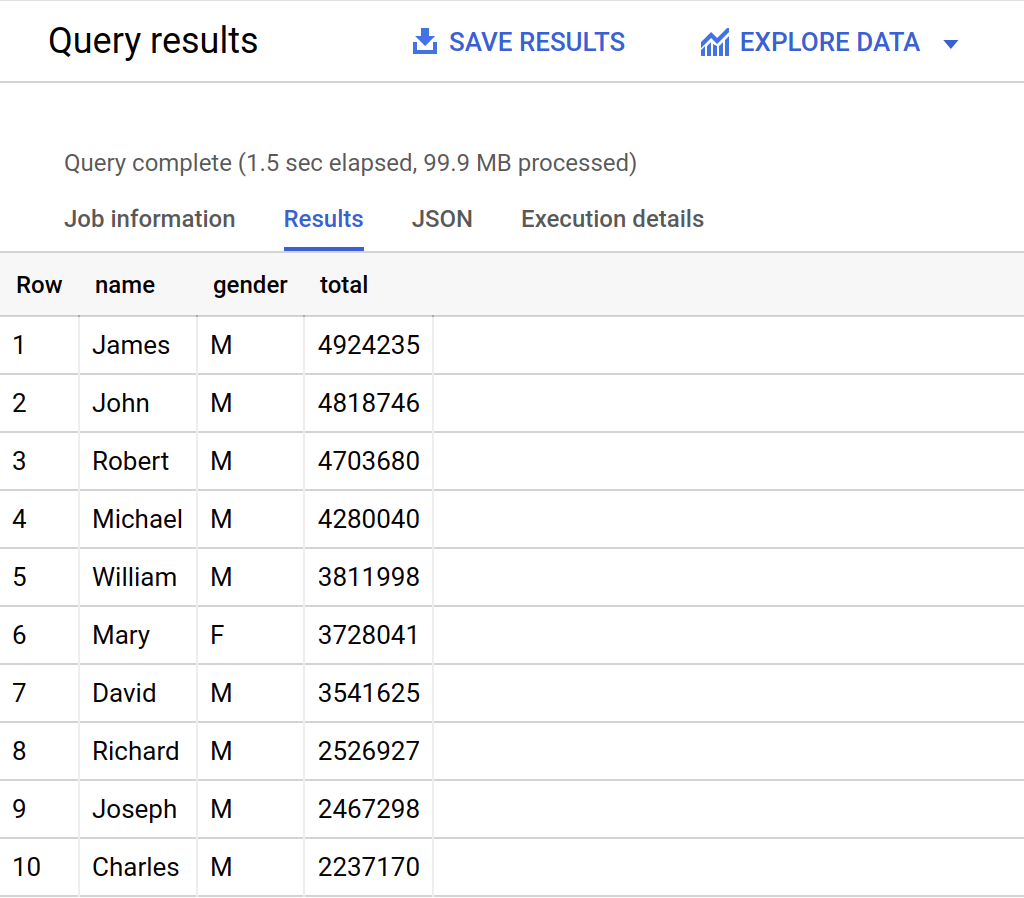
クエリエディタの下にクエリ結果が表示されます。[クエリ結果] セクションの上部には、クエリによって処理されたデータ量と経過時間が表示されます。また、時間の下の表にはクエリ結果が表示されます。ヘッダー行には、クエリの GROUP BY で指定した列の名前が含まれています。
[進行状況を確認] をクリックして、目標に沿って進んでいることを確認します。
タスク 3. カスタム テーブルを作成する
このセクションでは、カスタム テーブルを作成してデータを読み込み、それに対してクエリを実行します。
ローカルのパソコンにデータをダウンロードする
ダウンロードするファイルには、米国社会保障局から提供された、人気のある新生児の名前に関する約 7 MB のデータが含まれています。
- 新生児の名前の zip ファイルをローカルのパソコンにダウンロードします。
- パソコン上でファイルを解凍します。
-
yob2014.txtというファイルを開いて、データの内容を確認します。これは、名前、性別(MまたはF)、その名前の新生児の数を示す 3 つの列を含むカンマ区切り値(CSV)ファイルです。このファイルにはヘッダー行がありません。 - 後で確認できるように、
yob2014.txtファイルの場所をメモします。
タスク 4. データセットを作成する
このセクションでは、テーブルを格納するデータセットを作成し、プロジェクトにデータを追加して、クエリの対象となるデータテーブルを作成します。
データセットは、プロジェクト内のテーブルとビューへのアクセス制御に役立ちます。このラボではテーブルを 1 つしか使用しませんが、テーブルを格納するデータセットは必要です。
-
コンソールに戻り、[エクスプローラ] セクションでプロジェクト ID の横にある「アクションを表示」アイコンをクリックし、[データセットを作成] を選択します。
-
[データセットを作成する] ページで次の操作を行います。
- [データセット ID] に「
babynames」と入力します。 - [ロケーション タイプ] で [マルチリージョン] をオンにし、[us(米国の複数のリージョン)] を選択します。
- [デフォルトのテーブルの有効期限] はデフォルト値のままにしておきます。
現在、一般公開データセットは US マルチリージョン ロケーションに保存されています。わかりやすくするため、データセットを同じロケーションに配置します。
![[データセットを作成する] ページ。[データセットを作成] ボタンがハイライト表示されている。](https://cdn.qwiklabs.com/mXJBe%2ByNhGl%2FWDRjNaxWFbvRG7x8ezZ7K4aW27mSA4A%3D)
- パネルの下部にある [データセットを作成] をクリックします。
[進行状況を確認] をクリックして、目標に沿って進んでいることを確認します。
タスク 5. 新しいテーブルにデータを読み込む
このセクションでは、作成したテーブルにデータを読み込みます。
- [エクスプローラ] セクションで babynames データセットの横にある「アクションを表示」アイコンをクリックします。[開く] を選択し、[テーブルを作成] をクリックします。
別途指定のない限り、すべての設定にデフォルト値を使用します。
- [テーブルを作成] ページで次の操作を行います。
- [テーブルの作成元] のプルダウン メニューで [アップロード] を選択します。
- [ファイルを選択] で [参照] をクリックし、
yob2014.txtファイルを選択して [開く] をクリックします。 - [ファイル形式] で、プルダウン メニューから [CSV] を選択します。
- [テーブル] に「
names_2014」と入力します。 - [スキーマ] セクションで [テキストとして編集] をクリックし、次のスキーマ定義をテキスト ボックスに貼り付けます。
- [テーブルを作成] をクリックします(ウインドウの下部にあります)。
- BigQuery によってテーブルが作成され、データが読み込まれるのを待ちます。データの読み込み中は、[個人履歴] ペインでステータスを確認できます。
テーブルをプレビューする
- 左側のナビゲーション パネルで、[babynames] > [names_2014] を選択します。
- 詳細パネルで [プレビュー] タブをクリックします。
![行、name、gender、count の 4 つの列見出しの下に複数のデータ行を表示している [プレビュー] タブの画面](https://cdn.qwiklabs.com/K8qmzq%2Bv5GkyPNw3%2BmjeLQMt75wjZZWzIeNO7DZZ98M%3D)
タスク 6. テーブルに対してクエリを実行する
テーブルにデータが読み込まれたので、クエリを実行できます。手順は前の例とまったく同じです。ただし今回は、一般公開テーブルではなく自分のテーブルに対してクエリを実行します。
- [クエリ] > [新しいタブ] をクリックします。
- クエリエディタ内のデフォルトのクエリテキストを削除します。
- 次のクエリをコピーして、クエリエディタに貼り付けます。このクエリは、2014 年に米国で人気が高かった男の子の名前、上位 5 つを取得します。
- [実行] をクリックします。結果はクエリ ウィンドウの下に表示されます。
[進行状況を確認] をクリックして、目標に沿って進んでいることを確認します。
お疲れさまでした
ここでは、まず一般公開データセットに対してクエリを実行しました。次にカスタム テーブルを作成してデータを読み込み、それに対してクエリを実行しました。
次のステップと詳細情報
BigQuery の詳細については、BigQuery のドキュメントと BigQuery の一般公開データセットをご覧ください。
Google Cloud トレーニングと認定資格
Google Cloud トレーニングと認定資格を通して、Google Cloud 技術を最大限に活用できるようになります。必要な技術スキルとベスト プラクティスについて取り扱うクラスでは、学習を継続的に進めることができます。トレーニングは基礎レベルから上級レベルまであり、オンデマンド、ライブ、バーチャル参加など、多忙なスケジュールにも対応できるオプションが用意されています。認定資格を取得することで、Google Cloud テクノロジーに関するスキルと知識を証明できます。
マニュアルの最終更新日: 2023 年 10 月 2 日
ラボの最終テスト日: 2023 年 10 月 2 日
Copyright 2024 Google LLC All rights reserved. Google および Google のロゴは Google LLC の商標です。その他すべての企業名および商品名はそれぞれ各社の商標または登録商標です。