チェックポイント
Retrieve dataset files
/ 50
Publish the results to BigQuery
/ 50
Google Cloud での Cloud Dataprep の操作
このラボは Google のパートナーである Alteryx と共同開発されました。アカウント プロフィールでサービスの最新情報、お知らせ、特典の受け取りをご希望になった場合、お客様の個人情報が本ラボのスポンサーである Alteryx と共有される場合があります。
GSP050

概要
Cloud Dataprep は、Alteryx と共同で構築された Google のセルフサービス データ準備ツールです。このラボでは、Cloud Dataprep を使用して複数のデータセットのクレンジングとデータ品質の改善を行う方法について説明します。このラボの演習は、模擬のユースケース シナリオに基づいています。
ユースケース シナリオ
あなたは技術サービス会社で働いています。この会社では次の 3 つの月次サブスクリプション商品を販売しています。
- シルバー(価格: 1 か月あたり 9.99 ドル)
- ゴールド(価格: 1 か月あたり 14.99 ドル)
- プラチナ(価格: 1 か月あたり 29.99 ドル)
この会社ではプロモーション割引を実施することがあるため、一部の商品価格は上記の金額よりやや低くなることがあります。全体的な目標は、3 年間にわたる販売活動を郵便番号別に分析することです。
この作業を行うには、郵便番号情報を含む顧客連絡先データソースを、購入データソースから取得した販売データと結合する必要があります。データを結合したら、その結果を集計します。
学習内容
このラボでは、次のタスクの実行方法について学びます。
- Cloud Dataprep を使用して、データのクレンジングとプロファイリングを行う
- Cloud Dataprep を使用して複数のデータセットを統合、結合する
- Cloud Dataprep で数式を計算する
設定と要件
[ラボを開始] ボタンをクリックする前に
こちらの手順をお読みください。ラボの時間は記録されており、一時停止することはできません。[ラボを開始] をクリックするとスタートするタイマーは、Google Cloud のリソースを利用できる時間を示しています。
このハンズオンラボでは、シミュレーションやデモ環境ではなく、実際のクラウド環境を使ってご自身でラボのアクティビティを行うことができます。そのため、ラボの受講中に Google Cloud にログインおよびアクセスするための、新しい一時的な認証情報が提供されます。
このラボを完了するためには、下記が必要です。
- 標準的なインターネット ブラウザ(Chrome を推奨)
- ラボを完了するために十分な時間を確保してください。ラボをいったん開始すると一時停止することはできません。
ラボを開始して Google Cloud コンソールにログインする方法
-
[ラボを開始] ボタンをクリックします。ラボの料金をお支払いいただく必要がある場合は、表示されるポップアップでお支払い方法を選択してください。 左側の [ラボの詳細] パネルには、以下が表示されます。
- [Google コンソールを開く] ボタン
- 残り時間
- このラボで使用する必要がある一時的な認証情報
- このラボを行うために必要なその他の情報(ある場合)
-
[Google コンソールを開く] をクリックします。 ラボでリソースが起動し、別のタブで [ログイン] ページが表示されます。
ヒント: タブをそれぞれ別のウィンドウで開き、並べて表示しておきましょう。
注: [アカウントの選択] ダイアログが表示されたら、[別のアカウントを使用] をクリックします。 -
必要に応じて、[ラボの詳細] パネルから [ユーザー名] をコピーして [ログイン] ダイアログに貼り付けます。[次へ] をクリックします。
-
[ラボの詳細] パネルから [パスワード] をコピーして [ようこそ] ダイアログに貼り付けます。[次へ] をクリックします。
重要: 認証情報は左側のパネルに表示されたものを使用してください。Google Cloud Skills Boost の認証情報は使用しないでください。 注: このラボでご自身の Google Cloud アカウントを使用すると、追加料金が発生する場合があります。 -
その後次のように進みます。
- 利用規約に同意してください。
- 一時的なアカウントなので、復元オプションや 2 要素認証プロセスは設定しないでください。
- 無料トライアルには登録しないでください。
その後このタブで Cloud Console が開きます。

Cloud Shell をアクティブにする
Cloud Shell は、開発ツールと一緒に読み込まれる仮想マシンです。5 GB の永続ホーム ディレクトリが用意されており、Google Cloud で稼働します。Cloud Shell を使用すると、コマンドラインで Google Cloud リソースにアクセスできます。
- Google Cloud コンソールの上部にある「Cloud Shell をアクティブにする」アイコン
をクリックします。
接続した時点で認証が完了しており、プロジェクトに各自の PROJECT_ID が設定されます。出力には、このセッションの PROJECT_ID を宣言する次の行が含まれています。
gcloud は Google Cloud のコマンドライン ツールです。このツールは、Cloud Shell にプリインストールされており、タブ補完がサポートされています。
- (省略可)次のコマンドを使用すると、有効なアカウント名を一覧表示できます。
-
[承認] をクリックします。
-
出力は次のようになります。
出力:
- (省略可)次のコマンドを使用すると、プロジェクト ID を一覧表示できます。
出力:
出力例:
gcloud ドキュメントの全文については、gcloud CLI の概要ガイドをご覧ください。
タスク 1. Google Cloud Dataprep を開く
-
Cloud コンソールでナビゲーション メニューに移動し、[分析] 下の [Dataprep] を選択します。
-
Cloud Dataprep を使用するには、チェックボックスをオンにして Google Dataprep の利用規約に同意し、[同意する] をクリックします。
-
アカウント情報が Alteryx と共有されることを知らせるプロンプトが表示されたら、チェックボックスをオンにして [同意して続行] をクリックします。
-
[許可] をクリックして、Alteryx がプロジェクトにアクセスできるようにします。
-
ラボの認証情報を選択してログインし、[許可] をクリックします。
-
チェックボックスをオンにし、[同意する] をクリックして Alteryx の利用規約に同意します。
-
ストレージ バケットのデフォルトの場所を使用するように求められたら [Continue] をクリックします。
-
新規ユーザーの場合、チュートリアルが立ち上がり、データセットを選択するよう求められます。[キャンセル] をクリックするか、終了して、この画面を閉じます。
-
左上にある Dataprep アイコンをクリックして、ホーム画面に移動します。
タスク 2. データセット ファイルを取得する
このセクションでは、Dataprep で自動作成されたストレージ バケットに営業活動ファイルを追加します。
- Cloud コンソールに戻ります。
-
バケット名を取得します。ナビゲーション メニューから、[Cloud Storage] > [バケット] を選択します。
-
次のステップで使用するために Dataprep のバケット名をメモしておきます。
-
Cloud Shell のコマンドラインで次のコマンドを実行します。
[ご利用のバケット名]は Dataprep のバケット名に変更します。
次のような出力が返されます。
[進行状況を確認] をクリックして、目標に沿って進んでいることを確認します。
タスク 3. フローを作成する
[Cloud Dataprep] タブに戻ります。データをラングリングするには、フローを作成する必要があります。フローは、関連する一連のデータセットと、デートセット間の連結によって構成されます。
- 右隅にある [Create Flow] をクリックします。
- フローの名前に「
Qwiklab1」と入力します。フローの説明は空白のままで、[Ok] をクリックします。
この時点で、フローが作成されます。ユーザーを補助するため、Dataprep はフローの中にいくつかのプレースホルダを作成します。最初のステップは、データをインポートして Dataprep とフローに追加することです。
-
[Dataset] の下の [+] をクリックして新しいデータソースを追加し、[Import Datasets] リンクをクリックします。
-
左側のナビゲーション メニューで [
Cloud Storage] > [dataprep-staging-xxx...] > [gsp050] をクリックし、前のセクションで保存したサンプルデータにアクセスします。 -
リストにある各ファイルの横の [+] をクリックします。ファイルをクリックすると画面の右側に移動します。[Import & Add to Flow] をクリックしてデータセットをフローに追加します。
Cloud Dataprep の [Flow View] ページが再度開きます。追加したデータセットが含まれています。レシピと出力の追加のプレースホルダが作成されます。
![追加したデータセットを含む [Flow View] ページ](https://cdn.qwiklabs.com/SD7pn%2FeNWFITyNVQ9TRZzQybNOrUx%2FwRuOJEAg1QNks%3D)
タスク 4. 顧客データをクレンジングする
データの準備ができたら、データ準備レシピを設計して顧客のデータセットをクレンジングします。テンプレートで、すでに lab_2013_transactions.csv データを使ったレシピが追加されています。ここでは、このレシピをスキップして、独自のレシピを作成してみましょう。
- 新しいレシピを作成するには:
-
lab_customers.csvの横にあるプラスアイコン(+)をクリックします。 - [Add New Recipe] をクリックします。
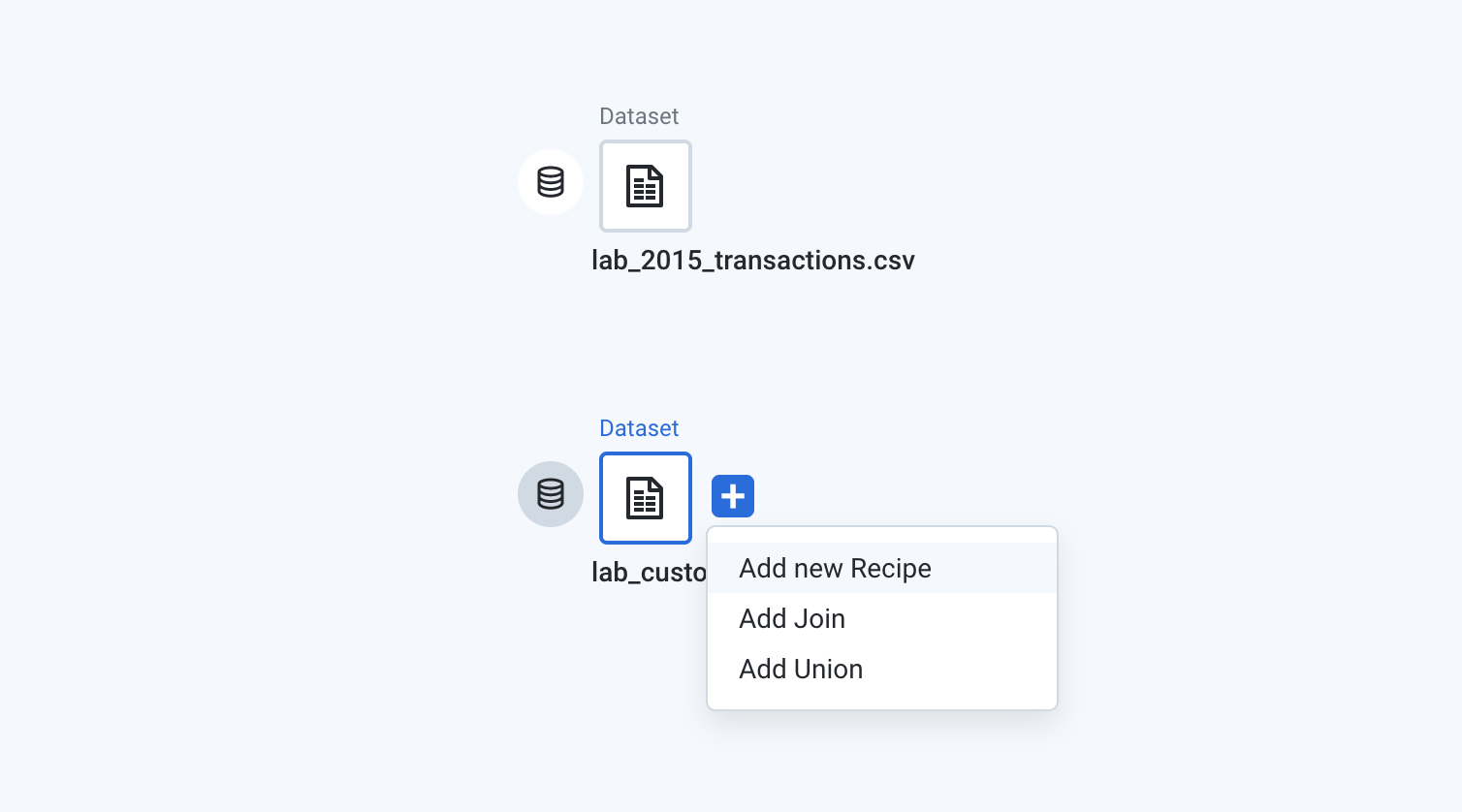
- その新しいレシピのノードを右クリックします。
- プルダウン メニューから [Edit name and description] を選択します。
- 名前を「
lab_customers」に変更し、[OK] をクリックします。
-
新しいレシピのノードが作成され、右側にパネルが開いて、そのレシピに関する情報(データや既存の変換手順など)が表示されます。
-
青色の [Edit Recipe] ボタンをクリックします(レシピのノードをダブルクリックする方法もあります)。
Cloud Dataprep で「Transformer グリッド」が表示されます。このワークシート形式のインターフェースを使用して、データ準備レシピの手順を設計することができます。Transformer ページでは、変換レシピを作成して、サンプルに適用した結果を確認できます。表示内容に問題がなければ、データセットに対してジョブを実行します。
各列には、名前と推定されたデータ型を示すアイコンが表示されます。列名の左にあるアイコンをクリックすると、可能性の高いデータ型が表示されます。
![column_id 列の展開メニュー。[More types] オプションがハイライト表示され、関連するサブメニューのオプションが表示されている。](https://cdn.qwiklabs.com/iCeKK4gKv1Rnegk8gST%2B%2FKIKDT0821sIyj%2FQKvfsO1c%3D)
列のオプションをクリックすると、右側に [Details] パネルが開きます。
この [Details] パネルは動的で、ユーザーが選択したものに関する情報(列の情報や変換の候補など)が表示されます。ここでは、[Details] パネルの右上にある [X] をクリックしてパネルを閉じます。
次のステップでは、グリッドビューでデータを探索し、レシピに変換手順を適用します。
Transformer グリッドを開くと、Cloud Dataprep は自動的にデータセットの内容をプロファイリングし、各列のヒストグラムとデータ品質インジケーターを生成します。データ準備プロセスのガイドとして、このプロファイル情報を使用することができます。
フィルタを適用する
- start_date 列まで右にスクロールします。列の一番上のバーを確認します。
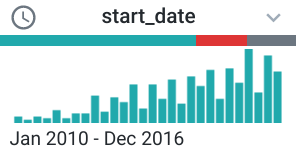
これはデータ品質バーです。緑色の部分は有効な値を表し、グレーの部分は欠損値や null 値を表します。赤いバーはデータ型が一致しないデータを表します。データ品質バーの各セクションをクリックすると、変換候補のデータ数とデータ品質の定義が表示されます。クリックしたバーのセクションに応じたデータ品質の定義に沿って、各データの状態(有効、空、無効)が判断されます。
start_date と end_date をフィルタとして使用し、start_date 列が空になっている連絡先を削除する変換処理を追加します。
-
start_date列のデータ品質バーでグレーの部分をクリックします。
Cloud Dataprep では、選択した部分に応じた変換候補のリストが生成されて右側に表示されます。候補カードの上にカーソルを合わせると、その候補を適用した場合にデータがどのようになるのかを Dataprep のプレビューで確認できます。カードを選択すると、Cloud Dataprep によってグリッドが更新され、この変換のプレビューが表示されます。
- 右側の [Delete rows with missing values in
start_date] 候補カードで [Add] をクリックします。
赤色でハイライト表示された行がデータセットから削除されます。
欠損値に値を入力する
end_date 列を見てみます。データ品質バーから、欠損値がある行が多数あることがわかります。この列を簡単に処理するには、これらの行の空の値に「2050/1/1」をセットします。
-
end_date列で、データ品質バーのグレーの部分をクリックします。
また一連の変換候補が生成されます。候補として [Set missing values to NULL()] が表示されます。この場合、Dataprep はユーザーが入力する正確な値を認識していないため、変更するためのテンプレートが自動で作成されます。
- 次に、候補カードの [Edit] をクリックします。
[Add Step] ビルダーが開きます。Cloud Dataprep の変換候補はすでに入力されていますが、コードを変更できます。
- [Formula] ボックスで
NULL()を'2050/1/1'(引用符付き)に置き換えます。数式は次のようになります。
![[Edit with formula] ボックス。[Formula] テキスト ボックスに数式が表示されている](https://cdn.qwiklabs.com/y8MEFY7BO87Im44u6P1HlFMYyDBpqC8HL81LJCcAWEY%3D)
- [Add] をクリックします。
これで lab_customers データセットのデータ品質の問題が解決されたため、データ品質バーのグレーの部分がなくなります。
タスク 5. 複数のトランザクション データセットを統合(Union)する
次に、トランザクション データセットを見てみましょう。
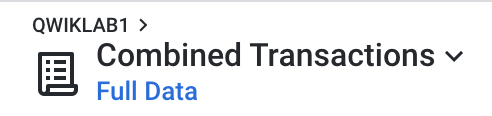
- 画面上部にあるフロー名 [
QWIKLAB1] をクリックします。

フロービューに戻ります。
2013 年、2014 年、2015 年のトランザクション データセットを統合して 1 つのデータセットを作成します。
-
lab_2013_transactionsデータセットをクリックします。 -
プラス記号 (+) をクリックして [Add new Recipe] を選択します。
Cloud Dataprep により、「Untitled recipe」という名前の新しいレシピおよびラングリングされたデータセットが作成されます。
-
この新しいラングリングされたデータセットを右クリックします。プルダウン メニューから [Edit name and description] を選択します。
-
名前を「
Combined Transactions」に変更し、[OK] をクリックします。
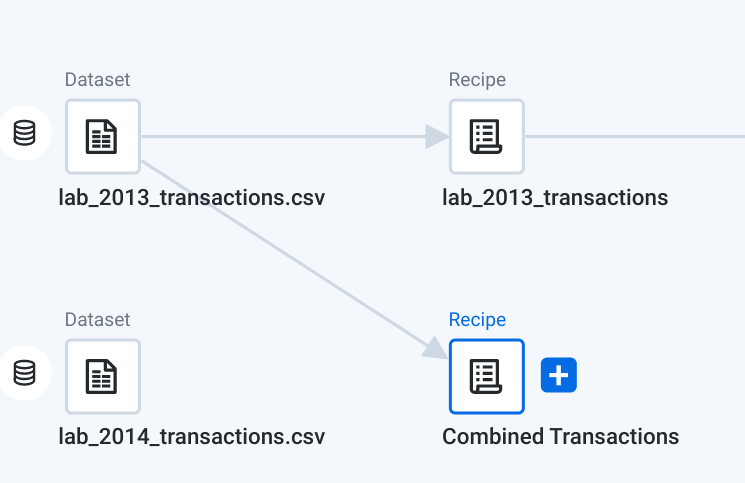
- [Combined Transactions] をダブルクリックしてレシピを編集します。Transformer グリッドでレシピが開きます。このグリッドのデータは、
lab_2013_transactions.csvデータセットの構造化データです。
統合(Union)変換を使用して、スキーマが同じ複数のデータセットを統合します。
- 変換する前に Transformer グリッドの左下を確認します。ここにメタデータが表示されます。

メタデータで、グリッドに読み込まれているデータの概要を確認できます。読み込まれたデータはデータセット全体のサンプル(10 MB まで)であることにご注意ください。
- Transformer の上部(レシピ名の付近)では、現在表示可能なサンプルを確認できます。

または
表示されるサンプルは、ソースの初期データです。小さなデータセット(10MB 未満)では、データセット全体が初期データサンプルに読み込まれます。
- 上部にあるレシピアイコンをクリックします。

-
[Add New Step] をクリックします。
-
検索欄に「Union」と入力して検索結果をクリックし、統合ツールを表示します。
[Union Output] に、データセットの出力スキーマが表示されます。各ボックスは列を表します。Cloud Dataprep では、統合変換を開始したデータセットのスキーマに基づいて出力スキーマが作成されます。この場合、「Combined Transactions」データセット内の列により、統合変換の出力に表示される列が決まります。
-
[Add Data] をクリックします。
-
lab_2014_transactionsのチェックボックスをオンにします。左下のプルダウンから [Align By Name] を選択して、[Apply] をクリックします。 -
[Add to Recipe] をクリックして、データセットを統合します。この統合をスクリプトに追加した後、
transaction_date列を確認します。
このデータセットには、2013 年 1 月から 2014 年 12 月までのレコードが含まれています。
- これで、3 つのデータセットのうち 2 つを統合しました。メタデータで行が追加されていることを確認できます。

タスク 6. レシピの手順を変更する
データの操作中に、特定の変換の微調整や削除を行う場合があります。Dataprep では作業内容を簡単に編集できます。ここまで、3 つのデータセットのうち 2 つを統合変換しました。残りのデータセットを統合する新しい手順を追加する代わりに、すでに行った手順を編集するだけで 3 つのデータセットを統合することができます。
- Undo アイコンをクリックして最後の操作を取り消します。この場合は、統合の手順です。
レシピが空になっていることがわかります。グリッドとメタデータも更新され、元の状態が反映されています。
-
Redo アイコンをクリックして統合の手順を戻します。
-
[Recipe] パネルで統合の手順を右クリックし、[Edit] を選択します。
-
統合ツールがもう一度開きます。[Add data] をもう一度クリックして
lab_2015_transactionsのチェックボックスをオンにします。左下のプルダウンから [Align By Name] を選択して、[Apply] をクリックします。 -
列対列のマッピングを確認します。[Add to Recipe] をクリックして、3 つのデータセットすべてを統合します。
-
この統合をスクリプトに追加した後、
transaction_date列を確認します。
このデータセットには、2013 年 1 月から 2015 年 12 月までのレコードが含まれています。メタデータ内に表示されている行数を確認します。
- フロー名 [
QWIKLAB1] をクリックして、フロービューに戻ります。
フローの表示が更新され、3 つのトランザクション データセットを統合した Combined Transaction データセットになっていることがわかります。
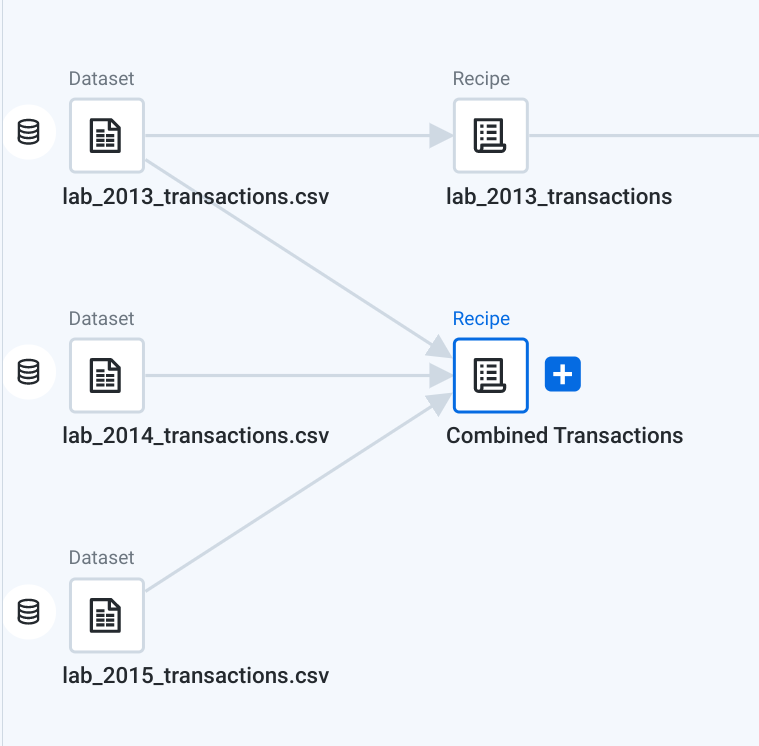
タスク 7. トランザクション データと顧客データを結合(Join)する
データセットを統合したので、次はトランザクション データに購入場所の情報を追加します。このために、顧客データをトランザクション データに結合します。結合を行うには、大きい方のデータセットをマスター データセット(結合の「左側」)にする必要があります。小さい方のデータセットは詳細データセット(結合の「右側」)にします。Cloud Dataprep では、結合を開始した方のデータセットが自動的にマスター データセットになります。
-
[Combined Transactions] をダブルクリックしてレシピをもう一度編集します。
-
Transformer ツールバーにある Join アイコンをクリックして結合ツールを開きます。
-
lab_customersデータセットをクリックしてもう一方のデータセットを取り込み、[Accept] をクリックします。 -
次の画面で結合キーと条件を編集します。左側には結合キーが一致するデータのプレビューが表示されます。右側には結合のタイプや結合キーを編集するオプション、結合の統計情報のプレビューが表示されます。Dataprep はデータセット間の共通の値に基づいて、適切な結合キーを自動的に推測します。
必要に応じて、結合キーを編集できます。結合キーのセクションにカーソルを合わせ、鉛筆(編集アイコン)をクリックして結合キーを変更するか、[Add] をクリックして他の結合キーを追加します。
Cloud Dataprep はこのようなデータセットに対して、customer_id 列で内部結合することを選択します。つまり、同じ customer_id を持つレコードを結合したものが出力データセットになります。
-
[次へ] をクリックします。
-
次の画面では、結合後に維持する列または破棄する列を選ぶことができます。[Output Columns] パネルで次の項目の横にあるチェックボックスをオンにして、これらの列を結合に追加します。
customer_id (Current)transaction_dateticket_priceproductaddress_stateaddress_zipregionstart_dateend_date
チェックボックスがオフになっている列は破棄されます。結果は次のようになります。
![さまざまな列のチェックボックスがオン / オフになっている [Output Columns] パネル](https://cdn.qwiklabs.com/MK4re4BcFH%2FhI0dClEf7PwdRitNOElAYNqjEXNcMU00%3D)
- [Review] をクリックし、Transformer グリッドで結合結果をプレビューします。
- [Add to Recipe] をクリックします。
タスク 8. 新しい列を作成して名前を変更する
最後に、レポートのデータをさらにクレンジングします。表示すべき値を含む複数の列を作成する必要があります。
Dataprep で変換を作成する別の方法(列メニューから作成)を見ていきましょう。
- [transaction_date] の横にあるプルダウン矢印 > [Extract] > [Datetime] > [Year (YYYY)] をクリックします。
新しい数式のビルダーが表示され、選択した操作がすでに入力されています。グリッド内にプレビューも生成されます。
- [Add] をクリックします。
year_transaction_date という新しい列が作成されていることを確認できます。前のステップでは、変換を編集するときに新しい列に名前を付けることができました。名前を付けていない場合、Dataprep はユーザーが選択した変換手順に応じて新しい列を生成します(または、元の列を選択していない場合は column# という名前が付きます)。
-
この列の名前は手動で変更できます。[year_transaction_date] の横にあるプルダウン矢印 > [Rename] をクリックします。
-
「
activity_year」と入力します。[Add] をクリックして変更を確定します。
注: [Add] をクリックしてマッピングを追加することで、この変換で出力された複数の列の名前を変更することができます。
タスク 9. BigQuery に結果を公開する
データの準備が完了したので、次は Cloud Storage に結果ファイルを作成します。Cloud Dataprep はデータ変換レシピを実行し、BigQuery エンジンを使用して出力ファイルを生成します。
-
Transformer グリッドの右上にある [Run] をクリックします。
-
[Run Job] ダイアログでジョブの実行と出力先を設定できます。デフォルトでは、Cloud Dataprep は Cloud Storage 上に CSV ファイルを作成します。
-
既存の公開操作の上にカーソルを合わせ、右側の [Edit] をクリックします。
-
左側の [BigQuery] タブをクリックします。
-
Dataprepデータベースを選択して、右側の [Create a new table] ボタンをクリックします。 -
新しいテーブル名に「
transactions_by_customer」と入力して、書き込みオプションに [Append to this table every run] を選択します。 -
下部にある [Update] をクリックして出力設定を更新します。
-
[Run] をクリックして、BigQuery ジョブを実行します。これには数分かかります。Dataprep の [Jobs] ページでジョブの処理状況を確認できます。完了すると、処理が正常に完了したことを示す次のようなメッセージが表示され、新しい BigQuery テーブルにデータが読み込まれます。
![「Combined Transactions」レシピの [Status] が「Completed」になっている [Flow jobs] ページ](https://cdn.qwiklabs.com/EUDqqmf7%2FAWL%2F2hiNJPU8Yew3ZdKUAqlcPZKf%2Fo0BNg%3D)
- 完了したジョブにカーソルを合わせて [Profile] をクリックして、データが整理されていることを確認します。次のようになります。
![[All data] セクションと [Results profile by column] セクションが表示されている [Profile] タブページ](https://cdn.qwiklabs.com/1MQ1urAEM%2FlJ%2FL837JCbsCFZ4byBTidgw%2B9mtARFp1U%3D)
-
BigQuery に対して直接クエリを実行し、結果を表示することもできます。Google Cloud コンソールで、[分析] > [BigQuery] に移動します。
Dataprepデータセットをクリックします。 -
クエリエディタに「
select * from Dataprep.transactions_by_customer;」と入力します。[Run] をクリックして公開されたデータを確認します。
Cloud Dataprep の操作は非常にシンプルです。直感的かつ視覚的なインターフェースを使用して、複数のデータソースのクレンジングとデータ品質の改善を簡単に行うことができます。
[進行状況を確認] をクリックして、目標に沿って進んでいることを確認します。
お疲れさまでした
これで「Google Cloud での Cloud Dataprep の操作」ラボは終了です。このラボでは、新しいフローを作成し、データを変換することから始めました。次に、Dataprep UI を使用して、乱雑なデータをフィルタリングし、複数のファイルを統合および結合し、列を作成して名前を変更する方法を学習しました。最後に、結果ファイルを作成して Google Cloud Storage にエクスポートしました。
次のステップと詳細情報
こちらで Dataprep Professionial Edition の 30 日間無料トライアルをご利用いただけます。必ず一時的なラボアカウントからログアウトし、Google Cloud の有効なメールアドレスで再ログインしてください。Google Cloud Marketplace でご利用いただけるプレミアム エディションでは、追加の接続性、パイプライン オーケストレーション、アダプティブ データ クオリティーなどの高度な機能もご利用いただけます。
Google Dataprep でデータの検出、クレンジング、品質の改善を行う方法については、入門ガイドでもご確認いただけます。
Google Cloud トレーニングと認定資格
Google Cloud トレーニングと認定資格を通して、Google Cloud 技術を最大限に活用できるようになります。必要な技術スキルとベスト プラクティスについて取り扱うクラスでは、学習を継続的に進めることができます。トレーニングは基礎レベルから上級レベルまであり、オンデマンド、ライブ、バーチャル参加など、多忙なスケジュールにも対応できるオプションが用意されています。認定資格を取得することで、Google Cloud テクノロジーに関するスキルと知識を証明できます。
マニュアルの最終更新日: 2023 年 9 月 27 日
ラボの最終テスト日: 2023 年 9 月 27 日
Copyright 2024 Google LLC All rights reserved. Google および Google のロゴは Google LLC の商標です。その他すべての企業名および商品名はそれぞれ各社の商標または登録商標です。