Prüfpunkte
Create a Kubernetes cluster and deployments (Auth, Hello, and Frontend)
/ 50
Canary Deployment
/ 50
Managing Deployments Using Kubernetes Engine
GSP053

Overview
Dev Ops practices will regularly make use of multiple deployments to manage application deployment scenarios such as "Continuous deployment", "Blue-Green deployments", "Canary deployments" and more. This lab teaches you how to scale and manage containers so you can accomplish these common scenarios where multiple heterogeneous deployments are being used.
Objectives
In this lab, you will learn how to perform the following tasks:
- Use the
kubectltool - Create deployment
yamlfiles - Launch, update, and scale deployments
- Update deployments and learn about deployment styles
Prerequisites
To maximize your learning, the following is recommended for this lab:
- You've taken these Google Cloud Skills Boost labs:
- You have Linux System Administration skills.
- You understand DevOps theory, concepts of continuous deployment.
Introduction to deployments
Heterogeneous deployments typically involve connecting two or more distinct infrastructure environments or regions to address a specific technical or operational need. Heterogeneous deployments are called "hybrid", "multi-cloud", or "public-private", depending upon the specifics of the deployment.
For this lab, heterogeneous deployments include those that span regions within a single cloud environment, multiple public cloud environments (multi-cloud), or a combination of on-premises and public cloud environments (hybrid or public-private).
Various business and technical challenges can arise in deployments that are limited to a single environment or region:
- Maxed out resources: In any single environment, particularly in on-premises environments, you might not have the compute, networking, and storage resources to meet your production needs.
- Limited geographic reach: Deployments in a single environment require people who are geographically distant from one another to access one deployment. Their traffic might travel around the world to a central location.
- Limited availability: Web-scale traffic patterns challenge applications to remain fault-tolerant and resilient.
- Vendor lock-in: Vendor-level platform and infrastructure abstractions can prevent you from porting applications.
- Inflexible resources: Your resources might be limited to a particular set of compute, storage, or networking offerings.
Heterogeneous deployments can help address these challenges, but they must be architected using programmatic and deterministic processes and procedures. One-off or ad-hoc deployment procedures can cause deployments or processes to be brittle and intolerant of failures. Ad-hoc processes can lose data or drop traffic. Good deployment processes must be repeatable and use proven approaches for managing provisioning, configuration, and maintenance.
Three common scenarios for heterogeneous deployment are:
- multi-cloud deployments
- fronting on-premises data
- continuous integration/continuous delivery (CI/CD) processe
The following exercises practice some common use cases for heterogeneous deployments, along with well-architected approaches using Kubernetes and other infrastructure resources to accomplish them.
Setup and requirements
Before you click the Start Lab button
Read these instructions. Labs are timed and you cannot pause them. The timer, which starts when you click Start Lab, shows how long Google Cloud resources will be made available to you.
This hands-on lab lets you do the lab activities yourself in a real cloud environment, not in a simulation or demo environment. It does so by giving you new, temporary credentials that you use to sign in and access Google Cloud for the duration of the lab.
To complete this lab, you need:
- Access to a standard internet browser (Chrome browser recommended).
- Time to complete the lab---remember, once you start, you cannot pause a lab.
How to start your lab and sign in to the Google Cloud console
-
Click the Start Lab button. If you need to pay for the lab, a pop-up opens for you to select your payment method. On the left is the Lab Details panel with the following:
- The Open Google Cloud console button
- Time remaining
- The temporary credentials that you must use for this lab
- Other information, if needed, to step through this lab
-
Click Open Google Cloud console (or right-click and select Open Link in Incognito Window if you are running the Chrome browser).
The lab spins up resources, and then opens another tab that shows the Sign in page.
Tip: Arrange the tabs in separate windows, side-by-side.
Note: If you see the Choose an account dialog, click Use Another Account. -
If necessary, copy the Username below and paste it into the Sign in dialog.
{{{user_0.username | "Username"}}} You can also find the Username in the Lab Details panel.
-
Click Next.
-
Copy the Password below and paste it into the Welcome dialog.
{{{user_0.password | "Password"}}} You can also find the Password in the Lab Details panel.
-
Click Next.
Important: You must use the credentials the lab provides you. Do not use your Google Cloud account credentials. Note: Using your own Google Cloud account for this lab may incur extra charges. -
Click through the subsequent pages:
- Accept the terms and conditions.
- Do not add recovery options or two-factor authentication (because this is a temporary account).
- Do not sign up for free trials.
After a few moments, the Google Cloud console opens in this tab.

Activate Cloud Shell
Cloud Shell is a virtual machine that is loaded with development tools. It offers a persistent 5GB home directory and runs on the Google Cloud. Cloud Shell provides command-line access to your Google Cloud resources.
- Click Activate Cloud Shell
at the top of the Google Cloud console.
When you are connected, you are already authenticated, and the project is set to your Project_ID,
gcloud is the command-line tool for Google Cloud. It comes pre-installed on Cloud Shell and supports tab-completion.
- (Optional) You can list the active account name with this command:
- Click Authorize.
Output:
- (Optional) You can list the project ID with this command:
Output:
gcloud, in Google Cloud, refer to the gcloud CLI overview guide.
Set the zone
Set your working Google Cloud zone by running the following command, substituting the local zone as
Get sample code for this lab
- Get the sample code for creating and running containers and deployments:
- Create a cluster with 3 nodes (this will take a few minutes to complete):
Task 1. Learn about the deployment object
To get started, take a look at the deployment object.
- The
explaincommand inkubectlcan tell us about the deployment object:
- You can also see all of the fields using the
--recursiveoption:
- You can use the explain command as you go through the lab to help you understand the structure of a deployment object and understand what the individual fields do:
Task 2. Create a deployment
- Update the
deployments/auth.yamlconfiguration file:
- Start the editor:
- Change the
imagein the containers section of the deployment to the following:
- Save the
auth.yamlfile: press<Esc>then type:
- Press
<Enter>. Now create a simple deployment. Examine the deployment configuration file:
Output:
Notice how the deployment is creating one replica and it's using version 1.0.0 of the auth container.
When you run the kubectl create command to create the auth deployment, it will make one pod that conforms to the data in the deployment manifest. This means you can scale the number of Pods by changing the number specified in the replicas field.
- Go ahead and create your deployment object using
kubectl create:
- Once you have created the deployment, you can verify that it was created:
- Once the deployment is created, Kubernetes will create a
ReplicaSetfor the deployment. You can verify that aReplicaSetwas created for the deployment:
You should see a ReplicaSet with a name like auth-xxxxxxx
- View the Pods that were created as part of the deployment. The single Pod is created by the Kubernetes when the
ReplicaSetis created:
It's time to create a service for the auth deployment. You've already seen service manifest files, so the details won't be shared here.
- Use the
kubectl createcommand to create the auth service:
- Now, do the same thing to create and expose the
hellodeployment:
- And one more time to create and expose the
frontenddeployment:
ConfigMap for the frontend.- Interact with the frontend by grabbing its external IP and then curling to it:
And you get the hello response back.
- You can also use the output templating feature of
kubectlto use curl as a one-liner:
Test completed task
Click Check my progress below to check your lab progress. If you successfully created Kubernetes cluster and Auth, Hello and Frontend deployments, you'll see an assessment score.
Scale a deployment
Now that you have a deployment created, you can scale it. Do this by updating the spec.replicas field.
- Look at an explanation of this field using the
kubectl explaincommand again:
- The replicas field can be most easily updated using the
kubectl scalecommand:
After the deployment is updated, Kubernetes will automatically update the associated ReplicaSet and start new Pods to make the total number of Pods equal 5.
- Verify that there are now 5
helloPods running:
- Now scale back the application:
- Again, verify that you have the correct number of Pods:
Now you know about Kubernetes deployments and how to manage & scale a group of Pods.
Task 3. Rolling update
Deployments support updating images to a new version through a rolling update mechanism. When a deployment is updated with a new version, it creates a new ReplicaSet and slowly increases the number of replicas in the new ReplicaSet as it decreases the replicas in the old ReplicaSet.
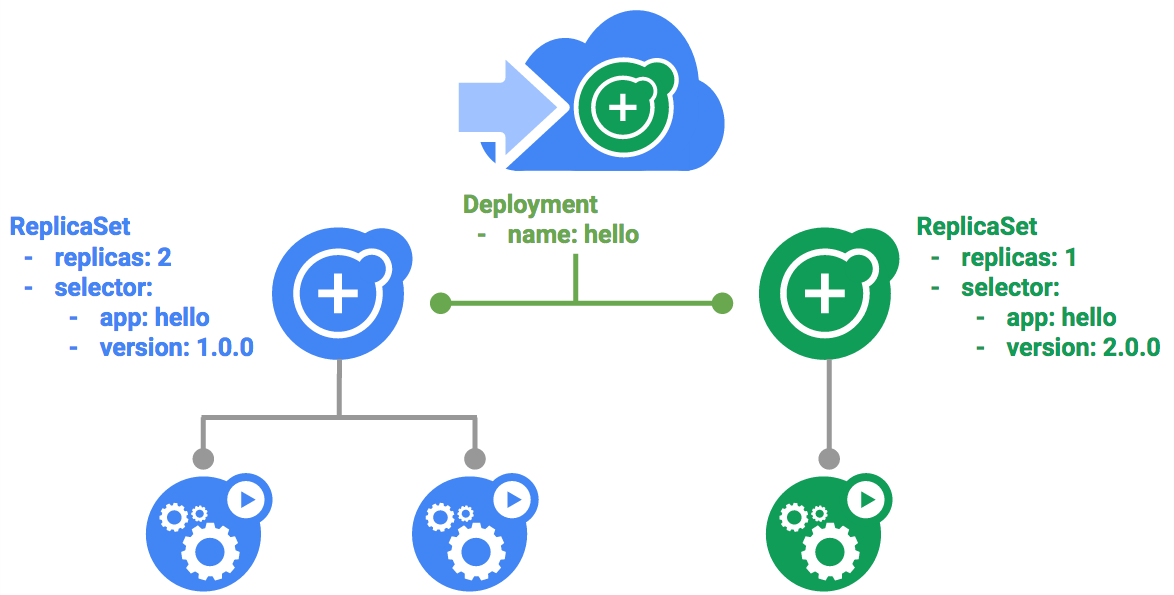
Trigger a rolling update
- To update your deployment, run the following command:
- Change the
imagein the containers section of the deployment to the following:
- Save and exit.
The updated deployment will be saved to your cluster and Kubernetes will begin a rolling update.
- See the new
ReplicaSetthat Kubernetes creates.:
- You can also see a new entry in the rollout history:
Pause a rolling update
If you detect problems with a running rollout, pause it to stop the update.
- Run the following to pause the rollout:
- Verify the current state of the rollout:
- You can also verify this on the Pods directly:
Resume a rolling update
The rollout is paused which means that some pods are at the new version and some pods are at the older version.
- Continue the rollout using the
resumecommand:
- When the rollout is complete, you should see the following when running the
statuscommand:
Output:
Roll back an update
Assume that a bug was detected in your new version. Since the new version is presumed to have problems, any users connected to the new Pods will experience those issues.
You will want to roll back to the previous version so you can investigate and then release a version that is fixed properly.
- Use the
rolloutcommand to roll back to the previous version:
- Verify the roll back in the history:
- Finally, verify that all the Pods have rolled back to their previous versions:
Great! You learned how to do a rolling update for Kubernetes deployments and how to update applications without downtime.
Task 4. Canary deployments
When you want to test a new deployment in production with a subset of your users, use a canary deployment. Canary deployments allow you to release a change to a small subset of your users to mitigate risk associated with new releases.
Create a canary deployment
A canary deployment consists of a separate deployment with your new version and a service that targets both your normal, stable deployment as well as your canary deployment.
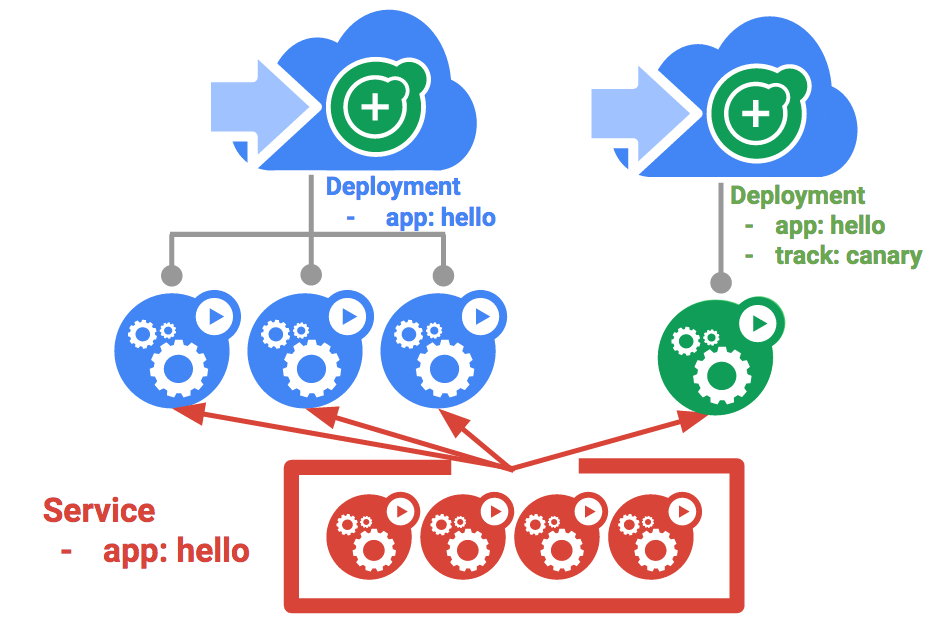
- First, create a new canary deployment for the new version:
Output:
- Now create the canary deployment:
- After the canary deployment is created, you should have two deployments,
helloandhello-canary. Verify it with thiskubectlcommand:
On the hello service, the app:hello selector will match pods in both the prod deployment and canary deployment. However, because the canary deployment has a fewer number of pods, it will be visible to fewer users.
Verify the canary deployment
- You can verify the
helloversion being served by the request:
- Run this several times and you should see that some of the requests are served by hello 1.0.0 and a small subset (1/4 = 25%) are served by 2.0.0.
Test completed task
Click Check my progress below to check your lab progress. If you successfully created Canary deployment, you'll see an assessment score.
Canary deployments in production - session affinity
In this lab, each request sent to the Nginx service had a chance to be served by the canary deployment. But what if you wanted to ensure that a user didn't get served by the canary deployment? A use case could be that the UI for an application changed, and you don't want to confuse the user. In a case like this, you want the user to "stick" to one deployment or the other.
You can do this by creating a service with session affinity. This way the same user will always be served from the same version. In the example below, the service is the same as before, but a new sessionAffinity field has been added, and set to ClientIP. All clients with the same IP address will have their requests sent to the same version of the hello application.
Due to it being difficult to set up an environment to test this, you don't need to here, but you may want to use sessionAffinity for canary deployments in production.
Task 5. Blue-green deployments
Rolling updates are ideal because they allow you to deploy an application slowly with minimal overhead, minimal performance impact, and minimal downtime. There are instances where it is beneficial to modify the load balancers to point to that new version only after it has been fully deployed. In this case, blue-green deployments are the way to go.
Kubernetes achieves this by creating two separate deployments; one for the old "blue" version and one for the new "green" version. Use your existing hello deployment for the "blue" version. The deployments will be accessed via a service which will act as the router. Once the new "green" version is up and running, you'll switch over to using that version by updating the service.
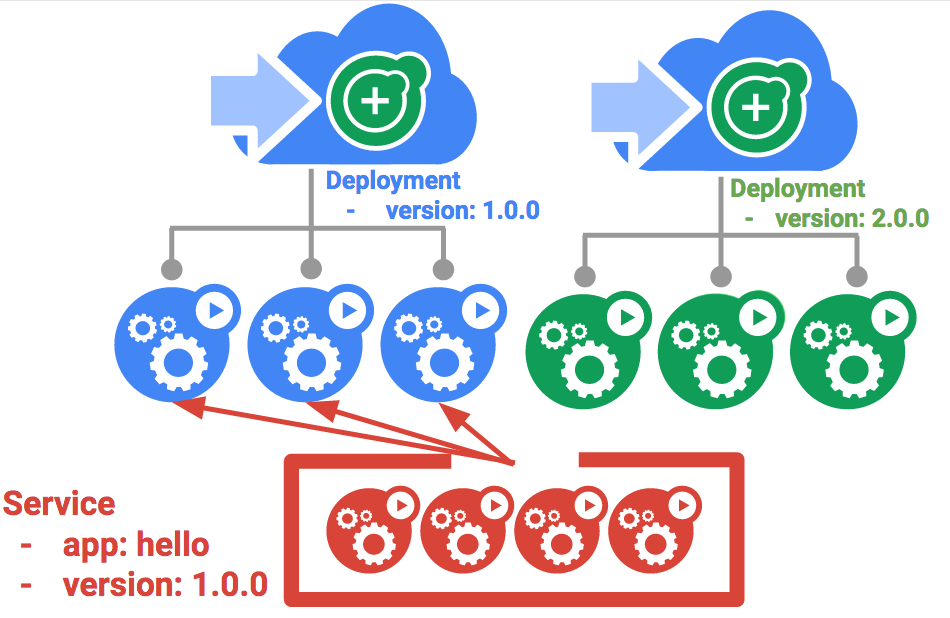
The service
Use the existing hello service, but update it so that it has a selector app:hello, version: 1.0.0. The selector will match the existing "blue" deployment. But it will not match the "green" deployment because it will use a different version.
- First update the service:
resource service/hello is missing as this is patched automatically.Updating using Blue-Green deployment
In order to support a blue-green deployment style, you will create a new "green" deployment for the new version. The green deployment updates the version label and the image path.
- Create the green deployment:
- Once you have a green deployment and it has started up properly, verify that the current version of 1.0.0 is still being used:
- Now, update the service to point to the new version:
- When the service is updated, the "green" deployment will be used immediately. You can now verify that the new version is always being used:
Blue-Green rollback
If necessary, you can roll back to the old version in the same way.
- While the "blue" deployment is still running, just update the service back to the old version:
- Once you have updated the service, your rollback will have been successful. Again, verify that the right version is now being used:
You did it! You learned about blue-green deployments and how to deploy updates to applications that need to switch versions all at once.
Congratulations!
You've had the opportunity to work more with the kubectl command-line tool, and many styles of deployment configurations set up in YAML files to launch, update, and scale your deployments. With this foundation of practice you should feel comfortable applying these skills to your own DevOps practice.
Next steps / Learn more
-
DevOps Solutions and DevOps Guides in the Google Cloud documentation.
-
On the Kubernetes website, connect with the Kubernetes Community!
Google Cloud training and certification
...helps you make the most of Google Cloud technologies. Our classes include technical skills and best practices to help you get up to speed quickly and continue your learning journey. We offer fundamental to advanced level training, with on-demand, live, and virtual options to suit your busy schedule. Certifications help you validate and prove your skill and expertise in Google Cloud technologies.
Manual last updated April 2, 2024
Lab last tested August 14, 2023
Copyright 2024 Google LLC All rights reserved. Google and the Google logo are trademarks of Google LLC. All other company and product names may be trademarks of the respective companies with which they are associated.