Checkpoints
Combine the data and export Parquet files
/ 35
Query data in BigQuery
/ 30
Query data in Dataproc and Spark
/ 35
Comparação entre a análise de dados no BigQuery e no Dataproc
- Informações gerais da atividade
- Cenário
- Configuração
- Tarefa 1: abra o JupyterLab em um cluster do Dataproc
- Tarefa 2: combine os dados e exporte arquivos Parquet
- Tarefa 3: consulte dados no BigQuery
- Tarefa 4: consulte dados no Dataproc e no Spark
- Tarefa 5: pare o cluster
- Resumo
- Conclusão
- Finalize o laboratório
 IMPORTANTE:
IMPORTANTE: Conclua este laboratório prático usando um computador ou notebook.
Conclua este laboratório prático usando um computador ou notebook. Só 5 tentativas são permitidas por laboratório.
Só 5 tentativas são permitidas por laboratório. É comum não acertar todas as questões na primeira tentativa e precisar refazer uma tarefa. Isso faz parte do processo de aprendizado.
É comum não acertar todas as questões na primeira tentativa e precisar refazer uma tarefa. Isso faz parte do processo de aprendizado. Depois que o laboratório é iniciado, não é possível pausar o tempo. Depois de 1h30, o laboratório será finalizado, e você vai precisar recomeçar.
Depois que o laboratório é iniciado, não é possível pausar o tempo. Depois de 1h30, o laboratório será finalizado, e você vai precisar recomeçar. Para saber mais, confira as Dicas técnicas do laboratório.
Para saber mais, confira as Dicas técnicas do laboratório.
Informações gerais da atividade
A análise de dados em nuvem é um campo que está evoluindo rapidamente, e a eficácia do trabalho dos analistas dessa área depende de um aprendizado contínuo de novas plataformas e tecnologias. Uma boa maneira de exercitar isso é comparar diferentes plataformas, como o BigQuery e o Dataproc.
O BigQuery e o Dataproc são ambas plataformas de processamento de dados na nuvem, mas que analisam as informações usando diferentes mecanismos de processamento de dados, dialetos SQL e ambientes de desenvolvimento.
O BigQuery é um data warehouse ideal para consultas interativas em grandes conjuntos de dados. Ele é fácil de usar e permite lidar com uma ampla variedade de tarefas de análise de dados.
O Dataproc é um serviço gerenciado Hadoop e Spark ideal para jobs de processamento em lote em grandes conjuntos de dados. O Dataproc é mais flexível do que o BigQuery, mas a configuração e o uso desse serviço podem ser mais complexos.
Tanto o BigQuery quanto o Dataproc são integrados a outros serviços do Google Cloud, o que facilita a movimentação de dados entre eles e a descoberta de origens de data lake.
Neste laboratório, você vai mesclar os dados de dois arquivos CSV em um arquivo Parquet. Depois, vai usar os dados combinados para comparar a análise feita com o BigQuery com uma análise que usa os mesmos dados, mas que é realizada com o Dataproc e o Spark.
Cenário
A TheLook eCommerce está testando um programa para começar a receber devoluções de pedidos on-line em qualquer loja física da empresa. O programa vai facilitar a devolução de itens por parte dos clientes, e o objetivo é aumentar as vendas e a satisfação do cliente.
Para monitorar o sucesso desse programa, Meredith, a líder da área de produtos, pediu para você preparar um relatório combinando os endereços das lojas e os dados de devoluções de cada uma delas. Esse relatório será usado para rastrear as devoluções por local e região. As informações também vão ajudar a determinar o sucesso do programa piloto em diferentes mercados.
Você começa analisando os dados coletados até o momento em cada local. Mas logo se dá conta de que o volume de dados é enorme! Você entra em contato com Artem, o arquiteto de dados, pedindo ajuda para trabalhar com o grande volume de dados que serão coletados, processados e analisados.
Artem sugere usar o Dataproc para combinar os dois arquivos CSV que já estão sendo usados em um único arquivo Parquet. O Parquet é um formato de dados em colunas otimizado para consultas analíticas rápidas. Artem também lembra que, como a TheLook eCommerce acabou de adquirir uma empresa que faz análises com o Spark, essa é uma ótima oportunidade de saber mais sobre o Dataproc e o Spark.
Ele propõe usar os dados combinados do relatório de Meredith para comparar duas formas de executar análises: uma centrada no BigQuery, um produto que você conhece bem, e outra centrada no Dataproc e no Spark. Ele lembra que essa é uma boa maneira de saber mais sobre o Dataproc e o Spark, e também de comparar as duas plataformas e descobrir qual delas é mais adequada para o programa piloto.
Você agradece Artem pelos conselhos. Mas antes de começar a comparar o BigQuery com o Dataproc e o Spark, é preciso mapear como será feita a coleta e o processamento dos dados que serão usados na comparação.
Você cria então um diagrama para ajudar a planejar melhor como vai combinar os dois arquivos CSV; a abordagem é unir os arquivos com o Spark SQL do Dataproc para renderizar um arquivo de devolução combinado no formato Parquet.
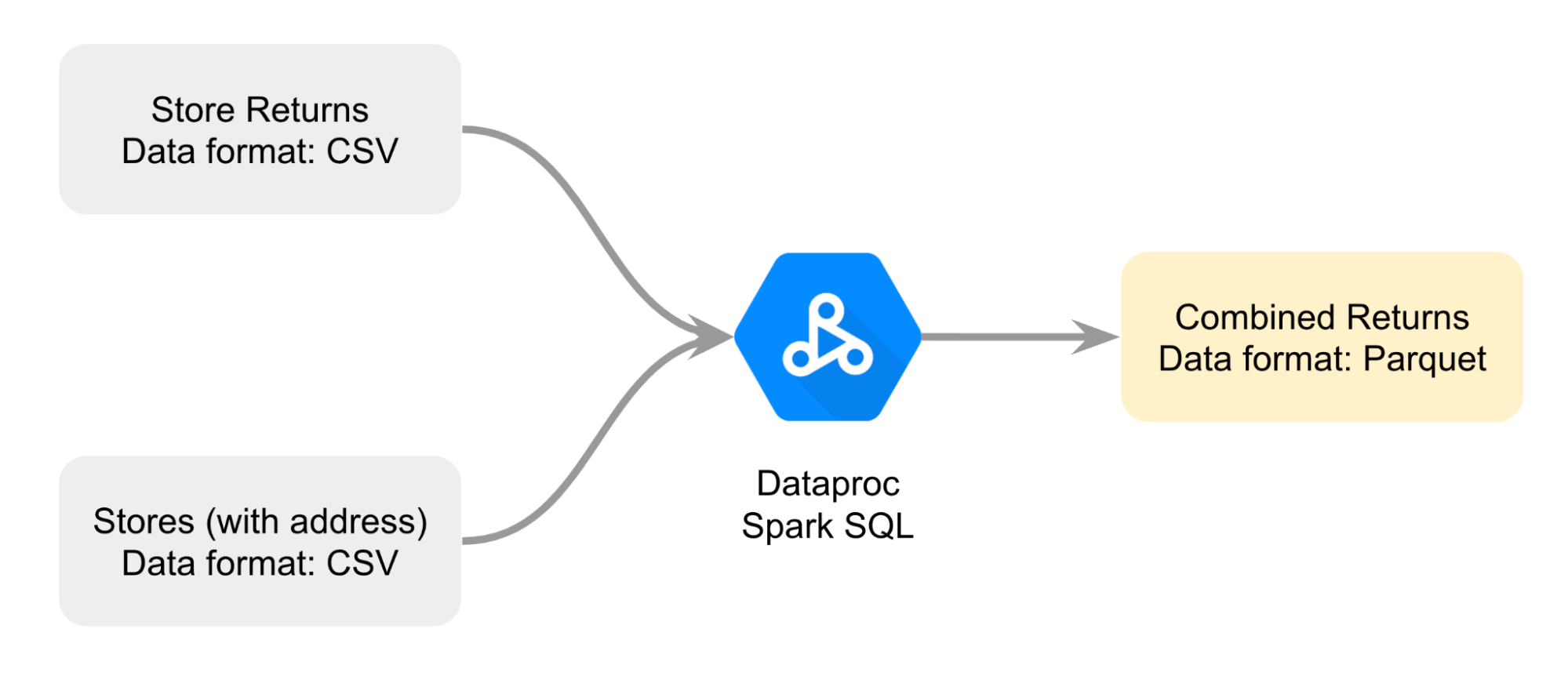
Esses são os dados que você vai usar como base para a comparação.
Você vai realizar a tarefa da seguinte forma: primeiro, você vai abrir um notebook do Jupyter em um cluster do Dataproc. Em seguida, vai seguir as instruções do notebook para unir os dois arquivos CSV e criar um arquivo Parquet. Depois, você vai carregar os dados do arquivo Parquet armazenado em um bucket do Cloud Storage em uma tabela padrão do BigQuery para analisá-los. Por fim, você vai fazer referência ao mesmo arquivo Parquet em um notebook do Jupyter em um cluster do Dataproc para comparar as duas análises de dados: uma delas usando o BigQuery e a outra usando o Dataproc e o Spark.
Configuração
Antes de clicar em "Começar o laboratório"
Leia as instruções a seguir. Os laboratórios são cronometrados e não podem ser pausados. O timer é iniciado quando você clica em Começar o laboratório e mostra por quanto tempo os recursos do Google Cloud vão ficar disponíveis.
Neste laboratório prático, você pode fazer as atividades por conta própria em um ambiente cloud de verdade, não em uma simulação ou demonstração. Você vai receber novas credenciais temporárias para fazer login e acessar o Google Cloud durante o laboratório.
Confira os requisitos para concluir o laboratório:
- Acesso a um navegador de Internet padrão (recomendamos o Chrome).
- Tempo para concluir o laboratório---não se esqueça: depois de começar, não será possível pausar o laboratório.
Como iniciar seu laboratório e fazer login no console do Google Cloud
-
Clique no botão Começar o laboratório. No painel Detalhes do laboratório à esquerda, você verá o seguinte:
- Tempo restante
- O botão Abrir console do Google Cloud
- As credenciais temporárias que você vai usar neste laboratório
- Outras informações, se forem necessárias
Observação: se for preciso pagar pelo laboratório, um pop-up vai aparecer para você escolher a forma de pagamento. -
Se você estiver usando o navegador Chrome, clique em Abrir console do Google Cloud (ou clique com o botão direito do mouse e selecione Abrir link em uma janela anônima). A página de login será aberta em uma nova guia do navegador.
Dica: é possível organizar as guias em janelas separadas, lado a lado, para alternar facilmente entre elas.
Observação: se a caixa de diálogo Escolha uma conta aparecer, clique em Usar outra conta. -
Se necessário, copie o Nome de usuário do Google Cloud abaixo e cole na caixa de diálogo de login. Clique em Próximo.
Você também encontra o Nome de usuário do Google Cloud no painel Detalhes do laboratório.
- Copie a Senha do Google Cloud abaixo e cole na caixa de diálogo seguinte. Clique em Próximo.
Você também encontra a Senha do Google Cloud no painel Detalhes do laboratório.
- Nas próximas páginas:
- Aceite os Termos e Condições
- Não adicione opções de recuperação nem autenticação de dois fatores nesta conta temporária
- Não se inscreva em testes gratuitos
Depois de alguns instantes, o console será aberto nesta guia.

Tarefa 1: abra o JupyterLab em um cluster do Dataproc
O JupyterLab pode ser usado para criar, abrir e editar notebooks do Jupyter em um cluster do Dataproc. Assim, você pode aproveitar os recursos do cluster, como o alto desempenho e a escalabilidade, e executar seus notebooks mais rapidamente e em conjuntos de dados maiores. Você também pode usar o JupyterLab para colaborar com outras pessoas em projetos.
Nessa tarefa, você vai usar o Dataproc para abrir um cluster existente do Dataproc e vai navegar até o JupyterLab para localizar os notebooks do Jupyter que serão usados para concluir as tarefas restantes desse laboratório.
- Na barra de título do console do Google Cloud, digite "Dataproc" no campo Pesquisar e pressione ENTER.
- Nos resultados da pesquisa, selecione Dataproc.
- Na página Clusters clique no nome do cluster listado, mycluster.
- Na página com guias de detalhes do Cluster, selecione a guia Interfaces da Web.
- Na seção Gateway do componente, clique no link do JupyterLab.
O ambiente do JupyterLab será aberto em uma nova guia do navegador.
- Localize o arquivo
C2M4-1 Combine and Export.ipynb, listado na barra lateral esquerda.
Tarefa 2: combine os dados e exporte arquivos Parquet
Para receber ajuda para identificar locais e mercados, Meredith precisa de informações sobre todas as devoluções e os endereços físicos onde elas foram feitas. Mas essas informações estão em dois arquivos CSV separados.
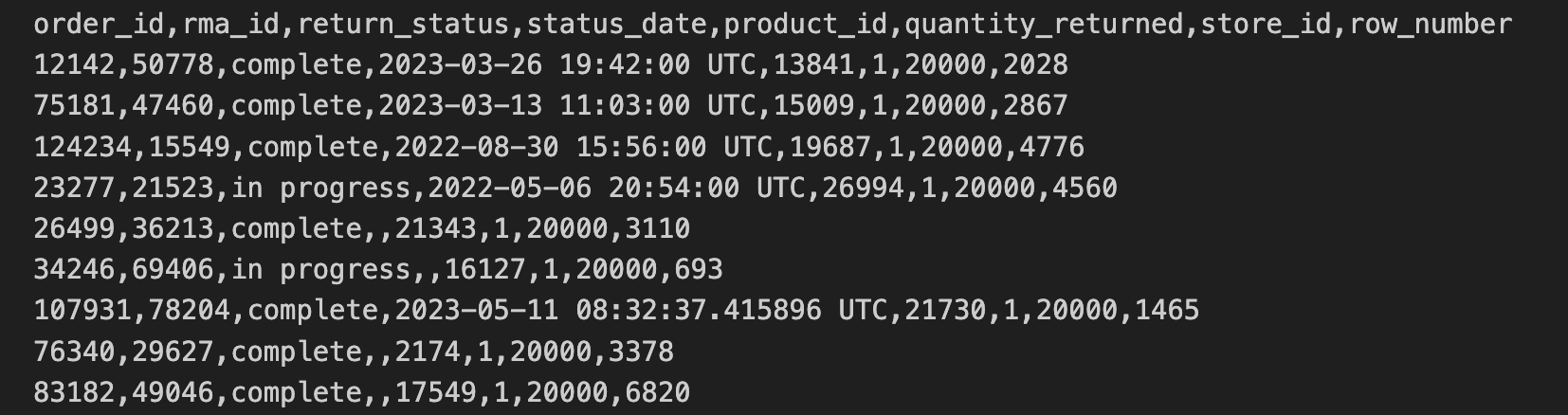
Os dados de devoluções para lojas foram exportados no formato CSV e copiados para um bucket do Cloud Storage. Esses dados incluem order_id, rma_id, return_status, status_date, product_ied, quantity_returned, store_id.
As primeiras 10 linhas do arquivo CSV de devoluções para lojas contêm o seguinte:
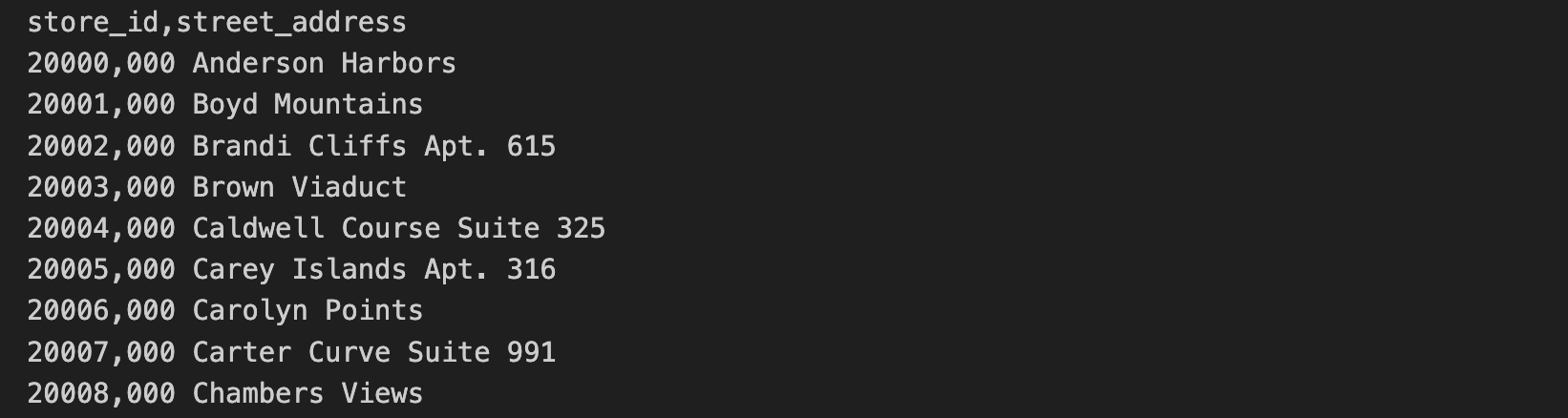
Os dados de endereços das lojas estão incluídos em um arquivo CSV separado. Esses dados incluem store_id e street_address.
As primeiras 10 linhas do arquivo CSV de endereços das lojas contêm o seguinte:
Nessa tarefa, você vai executar as consultas SQL e os comandos do Python contidos no arquivo C2M4-1 Combine and Export.ipynb para unir os dois arquivos CSV. Os arquivos combinados serão armazenados como um arquivo Parquet.
- Na barra lateral esquerda, clique duas vezes no arquivo
C2M4-1 Combine and Export.ipynbpara abri-lo no ambiente do JupyterLab.
Depois, siga as instruções do notebook e execute o código em cada uma das células.
- Clique em cada uma das células do notebook e, em seguida, clique no ícone Executar as células selecionadas e avançar (
) para executar todas as células. Ou pressione as teclas SHIFT+ENTER para executar o código. As células que dependem da saída de uma célula anterior DEVEM ser executadas em ordem. Se você cometer um erro e executar uma célula fora da ordem, clique no botão Atualizar (
) na barra de ferramentas do notebook para reiniciar o kernel.
- Analise as saídas de todas as células do notebook. Os dois arquivos CSV agora estão unidos, e o arquivo Parquet que você vai usar na próxima tarefa foi criado automaticamente.
Uma sessão Spark no Dataproc é uma maneira de se conectar a um cluster do Dataproc e executar aplicativos Spark. É a principal maneira de iniciar aplicativos Spark e criar Dataframes. Os Dataframes são tabelas que o Spark pode processar e usar para executar consultas. Com o Spark, também é possível ler e gravar dados em diferentes sistemas de armazenamento, como o Google Cloud Storage ou o BigQuery.
Neste notebook, você criou uma sessão Spark e carregou os dados de devoluções para lojas de um arquivo CSV em um DataFrame, uma tabela usada no Spark. Em seguida, você carregou os endereços de lojas de um segundo arquivo CSV, uniu os dois Dataframes e exportou a tabela única mesclada como um arquivo Parquet. Por fim, você usou uma consulta para alterar o nome de uma das colunas.
Dica: mantenha o notebook com as saídas abertas enquanto responde às perguntas abaixo.
Clique em Verificar meu progresso para conferir se você concluiu a tarefa corretamente.
Tarefa 3: consulte dados no BigQuery
Agora que o arquivo Parquet combinado foi criado e está armazenado em um bucket do Cloud Storage, tudo está pronto para comparar as duas maneiras de executar análises: uma centrada no BigQuery e outra centrada no Dataproc e no Spark.
Comece com o BigQuery, um data warehouse que usa o mecanismo do BigQuery para executar consultas e analisar dados.
Na última tarefa, você criou um arquivo Parquet e o armazenou em um bucket do Cloud Storage. Você tem duas opções para acessar esses dados no BigQuery: uma tabela externa ou uma tabela padrão. As tabelas externas se referem a dados armazenados fora do BigQuery, como no Google Cloud Storage. As tabelas padrão armazenam uma cópia dos dados diretamente no BigQuery.
Artem disse a você que o uso de tabelas padrão geralmente é a opção mais eficiente para trabalhar com big data, porque elas permitem que os dados sejam consultados e processados rapidamente. Então, você decide que uma tabela padrão é a melhor opção para essa tarefa.
Nessa tarefa, você vai carregar o arquivo Parquet em uma tabela padrão no BigQuery e vai executar uma consulta usando o GoogleSQL, o dialeto SQL usado no ambiente do BigQuery. Em seguida, você vai responder a perguntas para garantir que tem as informações necessárias para comparar o BigQuery com o Dataproc e o Spark na próxima tarefa.
-
Volte à guia do navegador do console do Google Cloud (onde a página do Dataproc ainda deve estar aberta), mantendo a guia do navegador do JupyterLab aberta.
-
No Menu de navegação do console do Google Cloud (
), clique em BigQuery > BigQuery Studio. O BiqQuery Studio é a principal forma de escrever e executar consultas no BigQuery.
-
No Editor de consultas, clique no ícone Escrever nova consulta (+) para abrir uma nova guia Sem título.
-
Copie a consulta a seguir na guia Sem título:
Essa consulta importa o arquivo Parquet para o BigQuery.
- Clique em Executar.
Um URI (Identificador de Recurso Uniforme) é o caminho para um arquivo em um bucket do Cloud Storage. Uma coleção de URIs pode ser fornecida como entrada para o comando LOAD DATA, colocando os URIs entre colchetes []. Isso indica que o valor é uma matriz de URIs.
O URI sempre começa com gs://, indicando que se trata de um recurso no Cloud Storage. O URI fornecido no exemplo acima filtra os arquivos com extensão .parquet, porque termina com *.parquet. O símbolo * é um caractere curinga, significando qualquer string.
Essa consulta retorna todos os arquivos no caminho gs://
- Copie a consulta a seguir no Editor de consultas:
Essa consulta retorna o número de linhas na tabela 'thelook_gcda.product_returns_to_store'.
- Clique em Executar.
Por padrão, quando você executa uma consulta no BigQuery Studio, ela é executada usando o dialeto GoogleSQL. O GoogleSQL é um superconjunto do dialeto SQL padrão, o que significa que ele inclui todas as consultas SQL padrão e extensões adicionais que facilitam o trabalho com grandes quantidades de dados e tipos de dados complexos no BigQuery.
- Copie a consulta a seguir no Editor de consultas:
Essa consulta exibe o número de devoluções recebidas por mês e por status.
- Clique em Executar.
Clique em Verificar meu progresso para conferir se você concluiu a tarefa corretamente.
Tarefa 4: consulte dados no Dataproc e no Spark
Agora que você concluiu sua análise no BigQuery, está tudo pronto para examinar a análise centrada no Dataproc e no Spark.
O Spark é o principal mecanismo de processamento de dados para análise de dados com o Dataproc. O Dataproc gerencia automaticamente o cluster do Spark e vem pré-instalado com o mecanismo, o que o torna uma opção conveniente e potente para a análise de dados.
O Spark também usa um dialeto SQL próprio, o Spark SQL. Assim como o GoogleSQL, o Spark SQL é um dialeto SQL. O Spark SQL é um dialeto SQL distribuído, o que significa que ele pode consultar e analisar dados distribuídos em várias máquinas no cluster do Spark.
Você vai usar um Notebook do Jupyter para executar consultas Spark SQL com o Dataproc e o Spark. Esse ambiente interativo permite que você escreva códigos e exiba facilmente as saídas deles.
Nessa tarefa, você vai executar consultas Spark SQL no arquivo Parquet que é referenciado do bucket do Cloud Storage. Em seguida, vai responder perguntas que vão ajudar você a concluir a comparação entre duas maneiras de executar análises: uma centrada no BigQuery e outra centrada no Dataproc e no Spark.
-
Volte à guia JupyterLab do seu navegador.
-
Clique duas vezes no arquivo
C2M4-2 Query Store Data with Spark SQL.ipynbpara abri-lo no ambiente do JupyterLab.
Siga as instruções do notebook e execute o código em cada uma das células.
-
Clique em cada uma das células do notebook e, em seguida, clique em Executar ou pressione SHIFT+ENTER para executar o código.
-
Analise os resultados das consultas Spark SQL no notebook.
Nesse notebook, você primeiro criou uma sessão Spark. Em seguida, você referenciou os dados dos arquivos Parquet no Cloud Storage usando o notebook do iPython e preencheu um DataFrame. Depois, você criou uma visualização para que o DataFrame pudesse ser usado com o Spark SQL. Na sequência, você executou uma consulta Spark SQL que retornou as três primeiras linhas do DataFrame. Por fim, você executou a mesma consulta que executou no BigQuery na etapa anterior.
Clique em Verificar meu progresso para conferir se você concluiu a tarefa corretamente.
Tarefa 5: pare o cluster
Como prática recomendada, antes de sair do ambiente, certifique-se de parar o cluster.
- Volte à guia BigQuery do seu navegador.
- Na barra de título do console do Google Cloud, digite Dataproc no campo Pesquisar.
- Selecione Dataproc nos resultados da pesquisa. A página Clusters será aberta.
- Na lista de clusters, marque a caixa de seleção ao lado de mycluster.
- Na barra de Ações, clique em Interromper.
Resumo
Analise a tabela a seguir, que resume as diferenças entre as duas formas de análise de dados abordadas neste laboratório: as análises realizadas com o BigQuery e aquelas feitas com o Dataproc e o Spark.
| Tarefa 3 | Tarefa 4 | |
|---|---|---|
| Produto central | BigQuery | Dataproc |
| Mecanismo de processamento de dados | BigQuery | Spark |
| Local dos dados | Tabela padrão do BigQuery | Arquivo Parquet no GCS |
| Dialeto SQL | GoogleSQL | Spark SQL |
| Ambiente de desenvolvimento | BigQuery Studio | Notebooks do Jupyter |
Conclusão
Bom trabalho!
Você coletou e processou com sucesso os dados necessários para o relatório de Meredith e usou os dados combinados para comparar duas abordagens de execução de análise: uma centrada no BigQuery, um produto que você já conhece, e outra centrada no Dataproc e no Spark.
Primeiro, você abriu um notebook do Jupyter em um cluster existente do Dataproc.
Depois, seguiu as instruções do notebook para unir dois arquivos CSV contendo dados de devoluções e endereços para criar um arquivo Parquet combinado e armazenar o arquivo Parquet em um bucket do Cloud Storage.
Seguindo o conselho de Artem, você usou o arquivo Parquet combinado para comparar as análises de dados usando o BigQuery e o Dataproc e o Spark para saber mais sobre os mecanismos de processamento de dados, dialetos SQL, locais dos dados e ambiente de desenvolvimento dessas análises.
Você está no caminho certo para entender como usar o Dataproc e o Spark para trabalhar com grandes conjuntos de dados.
Finalize o laboratório
Antes de encerrar o laboratório, certifique-se de que você concluiu todas as tarefas. Quando tudo estiver pronto, clique em Terminar o laboratório e depois em Enviar.
Depois que você finalizar um laboratório, não será mais possível acessar o ambiente do laboratório nem o trabalho que você concluiu nele.